1. The Problem
We had a customer who had built an antenna path gain/loss measurement system for use in a commercial satellite test system. The system included dual-redundant measurement paths. The redundant design gave the capability to run a calibration check on one set of instruments while performing live measurements using the other set. One important point is that the instruments were all connected to the HPIB interfaces of a single workstation.
Our customer uses VEE-Test in conjunction with an Ingres data base as the system control software. The data base is used to keep track of instrument use. So, while they are in the process of an antenna path measurement, our customer can query the data base to find out which instruments are not actively involved in the measurement and run a calibration check on them. Both the measurement and calibration routines are VEE programs.
Our customer observed that, during a calibration run (which entailed a several-minute procedure to check a spectrum analyzer), if they started an antenna path measurement, the HPIB buses containing the instruments undergoing calibration would be reset. This messed up the calibration run.
The reason this happens is that VEE does its HPIB communications at the interface level, sending the appropriate commands to access individual instruments. As part of this process, VEE will open and reset an HPIB interface the first time a VEE program schedules a live IO object for execution. The flow goes like this:
Succeeding presses on the run button do not cause VEE to open or reset the interfaces. The process of resetting the interface is necessary to prevent VEE from attempting to do IO on an interface in a potentially unknown state.
This situation highlights one of the most common areas of confusion that customers face as they move from single-tasking to multiple-process environments. Customers want to take advantage of the parallel operations multi-tasking systems offer, but fail to understand the implications of multiple-process access to a shared resource. We needed to give the customer a way to serialize access to the shared resources (in this case, the HPIB interfaces).
2. The Solution
The solution involved both a hardware change and some software components. It is necessary to isolate similar-functionality instruments on different HPIB buses in the redundant system. Consider what happens if you begin a calibration run which starts a several-minute operation on a spectrum analyzer that happens to be on the same bus as a spectrum analyzer that is to be used for antenna path measurements. We know that we need to serialize access to the bus to prevent the second VEE process from performing an HPIB reset while the calibration is in progress. So, while the first spectrum analyzer is performing its calibration routine, the second VEE process must wait for access to the bus. This can introduce an irritating measurement delay. The only reasonable way to handle this is to place one redundant set of instruments on one bus (or buses) and the second set on another bus (or buses).
Even given the redundant instrument bus isolation, the situation might arise where our customer needs to perform calibration on an instrument contained on the same interface as an instrument which performs an active measurement. To prevent the unwanted reset, we gave our customer a set of VEE compiled functions which would allow them to protect the critical measurement sections of their VEE programs. Both the calibration and measurement processes need to use the compiled functions in order for the protection mechanism to work. The remainder of the article discusses the implementation of those compiled functions.
3. Inter-Process Synchronization Library
This is a set of VEE compiled functions which allow a VEE programmer to create multiple-process, cooperative access to a single resource. If two or more VEE programs need to access a shared resource, they can coordinate their activities using the compiled functions we are about to describe. Note that this does not imply fully parallel access to the shared resource. What we can guarantee is that cooperating processes won't get access to a shared resource at a time when that access would disturb another process' use of that resource. So, the resource serves the needs of client processes in a serial fashion.
3.1. Design Considerations
There are a number of things to consider when you want to manage shared access to a single resource. Here, we enumerate those considerations.
3.1.1. Atomic Access
The mechanism we use to implement the critical section locking must guarantee atomic access. What this means is that when one process starts the routine to acquire a lock, it will always be allowed to finish acquiring the lock before another process is allowed to try to acquire the same lock.
3.1.2. Didn't Want to Rely on an External Application
We want the locking mechanism to be completely contained in a VEE compiled function. To rely on an external application increases the complexity of administering the system and can potentially introduce a non-atomic operation.
3.1.3. Blocking vs. Non-blocking Operation
We want our user to have the option of waiting indefinitely or of being handed an error return when attempting to acquire a lock that another process already owns. In the case where your program can do other things while waiting to acquire a lock, you could use the non-blocking versions of the locking mechanism and poll (every second or whatever) until you can acquire the lock.
3.2. Semaphores
We decided to use semaphores as the locking mechanism because they give use all the capabilities we describe above and because they are easy to use.
3.2.1. Background
Semaphores are owned by the UNIX kernel and give processes a common place to look if they are trying to coordinate their activities.
3.2.1.1. Keys
Most every form of Inter-process Communication (IPC) uses a unique identifier through which a process can specify which of the available IPC objects it wants to work with. In the case of semaphores, that identifier is an integer value. The way you figure out what the identifier is depends on the IPC object's intended use.
Let's take the case where you have a manager process that spawns children to do little pieces of a task. The children need to coordinate their activities among themselves. One way to achieve the coordination is for the parent process to create a private semaphore. This is a semaphore which can be accessed only by applications which have been given the semaphore identifier by the creating process. Private semaphores work well in a parent-child environment. The parent creates the semaphore and gives its identifier to each of the children who need it. No application outside that parent-child hierarchy can get access to the semaphores.
A second scenario is where independent processes (or peer processes) need to coordinate their activities. This is the case in our example where two VEE processes need access to a single resource. We need to provide a way for those processes to generate the identifier which points to the appropriate IPC object. The way UNIX provides for this is through the use of a key. In the preceding example, we said that an application could create a private semaphore. What actually happens is that you specify a particular value for the key when you create the semaphore, indicating that you want a private key. When cooperative processes want to create a key by which they can identify an IPC object, they use a function called ftok(). This function accepts a file name and a character. The cooperating processes must agree upon both the file and character constant they will use as parameters to ftok(). One important note here is that the key is generated not from the file name, but from the inode which is identified by the file name. So, you will want to choose a file that will always be present on your system and doesn't get moved around much (as would happen if the file is constantly being edited). The VEE-Test executable (or any other stable executable like /bin/ls) is a good choice for a file.
3.2.1.2. Types
The type of semaphore you choose will depend on its intended use. Generally, there are two kinds of semaphores. The use of the word "kind" or "type" might be a little confusing, however. When we say type, what we really mean is that the semaphore can behave in one of a few ways depending on how the application sets up the operations it performs on the semaphores.
3.2.1.2.1. Binary
A binary semaphore indicates a true or false condition. Usually, a binary semaphore is a good candidate for use in implementing a locking mechanism. Either the resource is locked or not.
3.2.1.2.2. Counting
A counting semaphore will increment its value to some maximum value as clients interact with it. Generally, this is good to restrict the number of clients that can access a resource simultaneously. For instance, if your customer had a license to use five copies of a piece of software, but had ten workstations in a cluster, you could use a counting semaphore to prevent unauthorized use by more than five clients.
3.2.1.2.3. Why We Used Counting Semaphores
We said previously that binary semaphores were a good choice when implementing a locking mechanism. There is one potential drawback with binary semaphores, however. The implementation involves creating a semaphore and then setting an initial value. These two are not atomic operations, so there is the possibility that a second process can try to alter the value of a semaphore after the first process has created it but before it was able to set the initial value.
What we did was to use a counting semaphore scheme and apply the restriction that the compiled functions which governed their use needed to be used in pairs. The compiled function that locked a semaphore must be followed at some point by a compiled function that unlocks the semaphore. This gains the atomicity you need but leaves the potential that a process could lock the semaphore and forget to unlock it, leaving the resource effectively unavailable. In response to this possibility, we created a compiled function that would let you destroy the semaphore lock. The next time a process tries to lock a resource, the compiled functions will automatically create a new semaphore.
3.2.1.3. Working with Semaphores
3.2.1.3.1. Atomicity Through Arrays
There two most frequently used functions you will use when working with semaphores are semop() and semctl(). semctl() is a non-atomic way to get and set the value of a semaphore and perform a few other operations. semop() allows you atomic access to a semaphore.
The argument to semop() is a pointer to a structure of type sembuf. The reason it is a pointer is that, to guarantee atomicity, the kernel needs to have all the instructions which affect a given semaphore grouped in memory. If you need to perform a series of atomic actions on a semaphore, you pass semop() an array of operations (an array of sembuf structures). When you pass an array, you really specify the address of the first element in the array, which is a pointer.
3.2.1.3.2. The sembuf Structure
The structure field contents tell the kernel what you want to do with the semaphore.
3.2.1.3.2.1. sem_num
When you create a semaphore, you can create a group of them, all identified by a single value. You would do this if you needed to control several aspects of a resource. When you need to tell the kernel to interact with one of the aspects, you do so by specifying its semaphore number within that set of semaphores. The sem_num field takes on the value zero to one-minus-the-number-of-semaphores in the set to identify to the kernel which semaphore you wish to work with. The first semaphore in the set is numbered zero, the second semaphore is numbered one, etc.
3.2.1.3.2.2. sem_op
The sem_op field in the structure tells the kernel what you want to do with the semaphore.
3.2.1.3.2.2.1. Positive
A positive number tells the kernel you want to increment the value of the semaphore by a given amount.
3.2.1.3.2.2.2. Negative
A negative number says that you want to decrement the semaphore value by the number's absolute value. One thing to note is that a semaphore's value can never be less than zero. If you give the kernel a negative number for sem_op that would cause the semaphore value to become negative, the kernel will either wait until the semaphore's value is incremented (by some other source) to the point where decrementing its value by the given amount would cause the semaphore value to become zero, or the kernel will issue an error. The user can choose the preferred behavior by setting the value of the sem_flg field.
3.2.1.3.2.2.3. Zero
Zero indicates that you want the given semaphore value to become zero before you proceed with further semaphore operations. This operation will either wait indefinitely until the semaphore value becomes zero or will return immediately with an error. The behavior you wish is specified by the value of the sem_flg field.
3.2.1.3.2.3. sem_flg
The two most common values for this field are zero (indicating that you don't want to alter the default behavior) and IPC_NOWAIT. The default behavior is that the kernel will put your process to sleep until it can complete the operation you requested. Specifying IPC_NOWAIT tells the kernel not to suspend your process but to return immediately with an error indicating that your process would have been put to sleep had you not specified IPC_NOWAIT.
3.3. The Compiled Functions
This is a set of VEE Compiled Functions which make use of counting semaphores to provide an inter-process synchronization mechanism. There are four Compiled functions, two of which are used to indicate that an entity has exclusive use of a shared resource, one that allows an entity to release its ownership of a resource, and one that destroys the locking mechanism. Because we use counting semaphores, it is necessary to balance the use of the locking and unlocking facilities. So, for every time an entity acquires a resource lock, that entity must follow by releasing the lock. In the case where an entity terminates before having had the opportunity to release a lock, it is possible to remove the locking mechanism entirely before a successive attempt to lock a resource.
3.3.1. Internal Routines
These are functions which the VEE compiled functions make use of but which are not available to be called from a VEE Call Function object. We can hide these functions simply by leaving them out of the VEE definition file.
3.3.1.1. Header Files
You will need the following header files to implement the inter-process locks:
3.3.1.2. Macros
Although not necessary, we defined a few macros that make it easier to represent compiled function return codes:
3.3.1.3. createKey
This function will create a key based on a file name we supply. The second argument to ftok() is a character value that we have chosen to be (what else?) 'V'. This key can them be used as the value from which to build a semaphore identifier.
key_t createKey(fileName)
char *fileName;
{
return(ftok(fileName, 'V'));
}
3.3.1.4. retrieveSemId
This function will return the integer value that is used in semaphore operations that involve the semaphore set identified by the key created above. We create a semaphore set that contains a single semaphore value. If the semaphore set does not exist, this function will create it, then return its semaphore identifier. The "0660" is similar to the permission structure that you would expect to find on a file. It says that the process which created the semaphore set, and any process in the creating process' process group, can read and alter semaphore values. You might want to change this to read "0666" if VEE processes spawned from different process groups will need to use these compiled functions.
int retrieveSemId(aKey)
key_t aKey;
{
return(semget(aKey, 1, IPC_CREAT|0660));
}
3.3.1.5. destroySem
This function will remove the semaphore set from the system.
int destroySem(semId)
int semId;
{
return(semctl(semId, 0, IPC_RMID));
}
3.3.1.6. semaphoreLock
This function will acquire an exclusive lock on a resource. It accepts an argument that allows the user to specify whether this function is to wait indefinitely to acquire a lock or to return immediately. It implements the lock by waiting for the semaphore value to become zero (indicating that no other entity has the resource locked) then by incrementing the semaphore value. So, while this process has an exclusive lock, another process that wants to acquire exclusive access to a resource, and that is using this same set of functions, will wait until this process unlocks. Again, the "wait" operation is given by setting the value of sem_op, in the first element in the array of the sembuf structures, to zero.
int semaphoreLock(semId, blocking)
int semId, blocking;
{
struct sembuf lockStruct[2];
lockStruct[0].sem_num=0;
lockStruct[0].sem_op=0;
if(blocking){
lockStruct[0].sem_flg=0;
}
else{
lockStruct[0].sem_flg=IPC_NOWAIT;
}
lockStruct[1].sem_num=0;
lockStruct[1].sem_op=1;
lockStruct[1].sem_flg=0;
return(semop(semId, lockStruct, sizeof(lockStruct)/sizeof(struct sembuf)));
}
3.3.1.7. semaphoreUnlock
This is the complement to the preceding function. It works by trying to decrement the semaphore value, indicating that a locked resource is being released. Note that we have specified the flag IPC_NOWAIT. We do this to prevent a deadlock situation which could arise due to the failure to check the return value from one of the locking functions.
int semaphoreUnlock(semId)
int semId;
{
struct sembuf unLockStruct;
int result;
unLockStruct.sem_num=0;
unLockStruct.sem_op=-1;
unLockStruct.sem_flg=IPC_NOWAIT;
result=semop(semId, &unLockStruct, sizeof(unLockStruct)/sizeof(struct sembuf));
switch(result){
case 0:
case EAGAIN:
break;
default:
return(E_SEMOP);
}
return(0);
}
3.3.2. blockingResourceLock
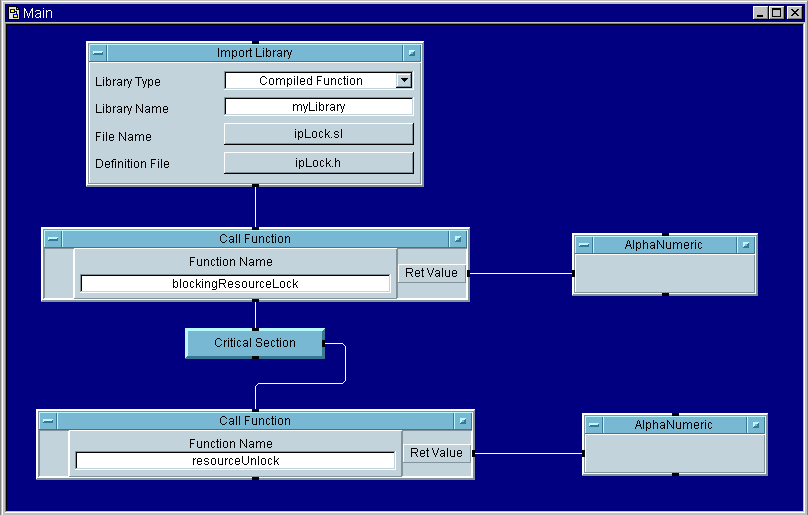
This Compiled Function will set a lock to gain exclusive access to a resource. After having used this function and having been granted exclusive access to a resource, no other entity (here we assume that the other entity also uses these locking mechanisms to request access to a resource) may gain access to the resource until the locking party calls the corresponding unlocking function. This call will block indefinitely if some other entity has a resource locked. Note that it is not necessary to specifically create any of the counting semaphores these compiled functions use. If they do not exist, the Compiled Functions will create them. If this function succeeds, you need to follow it with a balancing call to resourceUnlock. The following illustration demonstrates the use of this function.
long blockingResourceLock(){
key_t aKey;
int semId;
if((aKey=createKey("/usr/lib/veetest/veetest")) < (key_t) 0){
return(E_CREATE_KEY);
}
if((semId=retrieveSemId(aKey)) < 0){
return(E_CREATE_SEM);
}
return(semaphoreLock(semId, 1));
}
3.3.3. resourceLock
This is the asynchronous version of the resource-locking functions. This function returns the value zero if it successfully acquires exclusive access to a resource, otherwise it returns a negative value. When this function succeeds, you need to follow it, at some point, with a balancing call to resourceUnlock. Note that we repeatedly check the return value of this function until we get an indication that we have successfully acquired the lock. The following illustration demonstrates the use of this function.
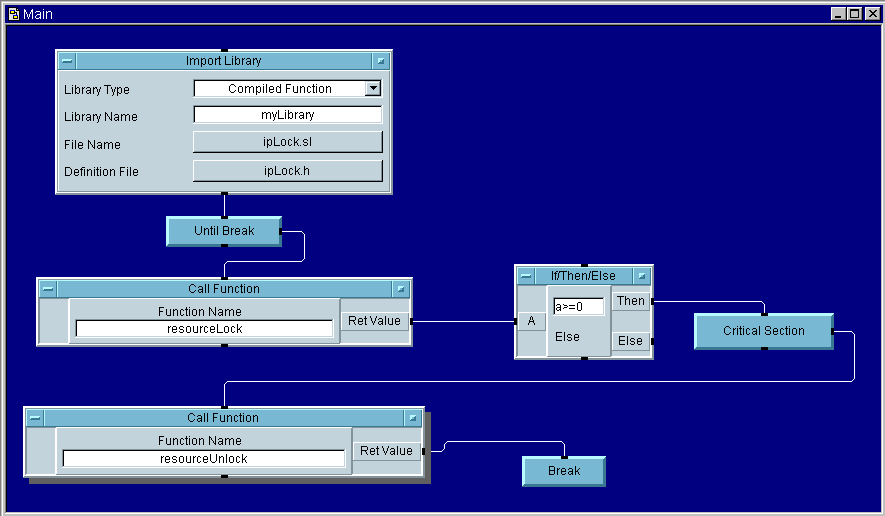
long resourceLock(){
key_t aKey;
int semId;
if((aKey=createKey("/usr/lib/veetest/veetest")) < (key_t) 0){
return(E_CREATE_KEY);
}
if((semId=retrieveSemId(aKey)) < 0){
return(E_CREATE_SEM);
}
return(semaphoreLock(semId, 0));
}
3.3.4. resourceUnlock
This function is used to release an exclusive lock on a shared resource. Its use is demonstrated in the two preceding illustrations. In the case where there are more calls to resourceUnlock than there are to either of the two locking functions, this function will return a negative value. Semaphores can never have a negative value, so in the case where the action of this function would be to decrement a counting semaphore to a value less than zero, the default action would be to block until the semaphore took on a value far enough above zero for this function to proceed. The resourceUnlock function will not block when it encounters the situation we describe here; it will return a negative value.
int resourceUnlock(){
key_t aKey;
int semId;
if((aKey=createKey("/usr/lib/veetest/veetest")) < (key_t) 0){
return(E_CREATE_KEY);
}
if((semId=retrieveSemId(aKey)) < 0){
return(E_CREATE_SEM);
}
return(semaphoreUnlock(semId));
}
3.3.5. destroyResourceLock
If, for some reason, you wish to remove the semaphore set from your system, you may do so using this function.
long destroyResourceLock(){
key_t aKey;
int semId;
if((aKey=createKey("/usr/lib/veetest/veetest")) < (key_t) 0){
return(E_CREATE_KEY);
}
if((semId=retrieveSemId(aKey)) < 0){
return(E_CREATE_SEM);
}
return((long)destroySem(semId));
}
3.4. Compiled Function Definition File
The contents of the VEE Compiled Function definition file look like this:
long resourceLock(); long blockingResourceLock(); long resourceUnlock(); long destroyResourceLock();
3.5. Make File
This make file is intended for use on HP-UX series 300, 400, and 700 computers.
all: ipLock.sl
ipLock.o: ipLock.c
cc +z -c ipLock.c
ipLock.sl: ipLock.o
ld -b -o ipLock.sl ipLock.o
chmod 555 ipLock.sl
rm -f ipLock.o
The following make file is intended for use on those versions of SunOS which support System V IPC.
all: ipLock.so
ipLock.o: ipLock.c
cc -g -pic -c ipLock.c
ipLock.so: ipLock.o
ld -o ipLock.so -assert pure-text ipLock.o /lib/shlib.etc/libcs5_pic.a
4. Utility Routines
There are two HP-UX commands that may prove useful as you experiment with the use of these functions. The first is ipcs. This command will display all of the (IPC) objects present in your system. You can use this to identify the semaphores which this set of Compiled Functions uses. The second is ipcrm. This command will allow you to remove IPC objects from your system. If you want to remove the semaphores that these Compiled Functions create, you could use the ipcs command to locate the identifier for the semaphore set, then use the command ipcrm -s semaphoreId to remove them.
5. Source Files