A Gentle Introduction to Wavelets
This is a paper written out of frustration.
This summer I decided to go to the SigGraph ’96 graphic conference in New Orleans. Through the courses I attended there I got really interested in the recent developments in wavelet theory and applications (image synthesis, compression etc.) Having returned to Cambridge, I looked up resources in both libraries and on the WWW on wavelets, and to my dismay I found none that I liked. Some were extremely technical and often I found the math to be way over my head, others went around the subject in dwindling loops, in an attempt to cover only the recent applications of wavelets but with little if any mathematical formalism.
I decided to write this paper primarily because I learn best by ‘typing out’ my thoughts. After wading through about 4-5 printed papers, I finally feel that I have a decent understanding of the basic concepts behind wavelets and I want to solidify them by presenting them in this paper.
This paper is a synthesis of a number of papers (all of which are listed in the bibliography). There is little if any original work : this paper is only intended as a ‘teaching tool’ if you will. I intend to make it available on the WWW, even add it to the ‘Wavelets Resources’ home page at www.mathsoft.com, if the maintainers find it worthwhile.
I would love to hear comments, criticism, suggestions about it. E-mail is probably the easiest way to get in touch with me (surdules@fas.harvard.edu).
The paper has been written entirely in Microsoft Word 7.0 (with Equation Editor); the numerical analysis and the graphs have been done in Microsoft Excel 7.0. You can get this paper (and attached Excel document) in both their original form, as well as a PostScript format.
Contents
1. What are Wavelets ?
1.1 Historical Perspective
1.2 Paper Outline
2. Mathematical Foundations of the Haar Wavelet
2.1 Definition and Basic Properties
2.2 Haar Functions as an Orthonormal Basis
2.3 Haar Coefficients and the Scaling Function
2.4 Recursive Algorithm for Computing Haar coefficients
2.5 Multiresolution Analysis
3. Algorithms and Visualization
4. Thresholding Techniques
5. Lifting
6. Application : Fast Multiresolution Image Querying
7. Bibliography :
1. What are Wavelets ?
In a strictly mathematical sense, a wavelet is a function with certain properties. This function is used as a building block for analyzing other functions at various ‘detail levels’. Imagine a smooth billiards ball : you can build an almost identical ball out of Lego blocks. If you use large and blocky Lego pieces, you will get a very rough approximation of the billiards ball; the smaller the Lego blocks, the better the approximation. A wavelet is very much like a Lego block : you can choose how ‘large’ the wavelet is by choosing a certain scaling factor; you can also ‘shift’ the wavelet around by a displacement factor so that it ‘clicks’ together with other wavelets and forms the billiards ball.
The notion of wavelet is more commonly used to denominate the actual scaling and displacement factors mentioned above : given a certain function, we’re interested in obtaining those particular coefficients and we call that a ‘wavelet’ (or, in this paper, the ‘wavelet vector’). Certainly, once we know how to compute the wavelet of a certain function or a certain data set, we can obtain an approximation of that function (or data set) by a reversal of the computation :
Data Set Þ Wavelet Decomposition ÞWavelet Composition Þ Data Set
The real power of the wavelets resides in the ability to ‘drop’ some of the components of the wavelet vector, without greatly affecting the approximation of the data set. Typically, the size of a wavelet is about the same as the size of the discrete data set we’re analyzing. However, depending on the structure of the wavelet, it is sometimes possible to discard 80% of the wavelet and still obtain a really good approximation of the initial data set (for example, the FBI uses a 20:1 wavelet based compression for shrinking the size of the fingerprints stored in their databases). This processing of ‘discarding coefficients’ from the wavelet is called thresholding.
Data Þ W-let Decomposition ÞThresholding Þ W-let Composition ÞData
In addition to compression, by intelligently choosing wavelet coefficients to drop, one can rid a data set of certain unwanted artifacts. For example, Coifman and his Yale team used wavelets to ‘clean up’ old and noisy sound recordings.
1.1 Historical Perspective
The idea behind wavelets is not new : in the early 1800’s, Joseph Fourier discovered that it’s possible to superpose sines and cosines to represent other functions. His claim was that any 2p periodic function f(x) can be represented as follows :
![]()
where
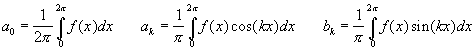
In other words, any function can be approximated via a ‘series’ of sines and cosines, properly shifted and scaled.
The main problem with Fourier series is that they’re not well localized : if you only want to study a function on a given interval [a, b], you need to involve all of the Fourier coefficients (ak, bk). With wavelets, you only need to choose the relevant coefficients for that particular interval (we’ll see later exactly how to choose them). Additionally, the wavelet coefficients are much simpler to compute than the Fourier coefficients above (which, as you see, all involve computing non-trivial integrals).
Fourier series are ‘bad’ at approximating spikes (or functions that have very localized features) : this is because, as you notice, the sines and cosines involved in Fourier analysis ‘stretch’ out to infinity and have a tendency to want to repeat certain features all throughout their domain.
1.2 Paper Outline
Here’s how this paper is laid out :
Section 2 : mathematical foundations. This paper is dedicated entirely to the study of the Haar wavelet (which is the simplest of all wavelets). This section will formalize the study (and applications) of the Haar wavelet on a mathematical basis.
Section 3 : algorithmic analysis of the Haar wavelet. In this section I intend to show how to compute the wavelet of a certain data set using a Haar based decomposition.
Section 4 : thresholding. This section presents some of the common thresholding techniques used in data analysis and compression. We’ll apply them succinctly to a small data set and inspect the results.
Section 5 : lifting. How to compute the wavelet of a data set ‘in place’.
Section 6 : application. This section will present, in detail, the algorithms used in [1].
2. Mathematical Foundations of the Haar Wavelet
2.1 Definition and Basic Properties
The Haar wavelet is defined as follows :
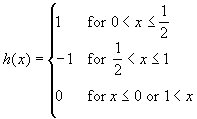
Graphically, the function is very simple :
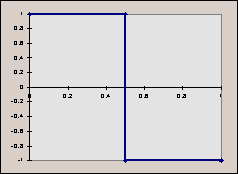
The Haar wavelet is also known as a ‘mother wavelet’ (or ‘the’ mother wavelet for having been the first wavelet function to be used extensively). It’s important to notice that the integral of the Haar wavelet over its domain is 0 (the two sides of the function cancel each other out). The integral of the Haar function when scaled by any given factor is also 0 (we’re only increasing each side by the same amount, but they still cancel out).
In order to scale and shift the Haar wavelet, we define a generic Haar function as follows :
![]()
The reason we choose to scale ‘x’ by 2j (a power of 2) will become apparent later. It’s important to keep in mind that both j and k are integers. Consider the graphs of some of these ‘scaled’ functions (in order from left to right, top to bottom, we have h10, h11, h20, h21, h22). Things to notice : (a) for any given value of j, the graphs do not overlap. (b) the graphs fall entirely in a ‘power of 2 subdivision’ of [0, 1] (in other words, their domains are of the form [2-a, 2-a+1], where a is an integer). So, for increasing values of ‘j’, we know that the graph of the function will fall entirely ‘beneath’ the graph of a function with a lower ‘j’ (a ‘previous’ function in the sequence).
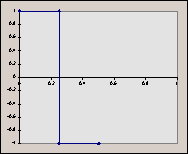
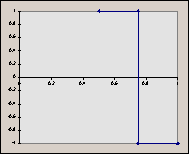
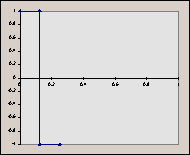
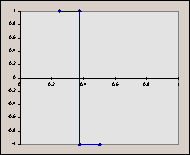
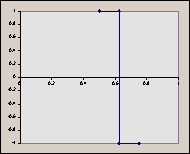
2.2 Haar Functions as an Orthonormal Basis
The functions hjk form an orthogonal basis for L2(R). This means is that any square integrable function, whose integrals is finite, can be expressed as a linear combination of a certain number of these hjk functions. Let’s prove that the basis is indeed orthogonal, and then let’s compute the value of ‘const’ (from the definition) :
1). Orthogonality :
We want to prove that the inner product <hjk, hj’k’> is 0 whenever j = j’ and k = k’ are not satisfied simultaneously (in other words, any two distinct functions in the basis are orthogonal). The inner product over this particular basis is defined as the integral of the product of the two functions :
![]()
The above relation is apparent :
Suppose j is different from j’ (and, WLOG, consider j < j’). Take a look at the functions above : since j and j’ are integers, the graph of hj’k’ will fall entirely in a power of 2 subdivision of the interval [0, 1]. Since the graph of hjk is ‘larger’ and falls as well in power of 2 subdivision of the unit interval, it must be that the graph is hj’k’ is either : (a) contained entirely in the set where hjk is 0 : in this case the integral is 0 because the product is 0. (b) contained entirely in the set where hjk is positive : in this case, all we’re doing is integrate a scaled version of hj’k’ by some constant : this integral is also 0, as stated at the beginning of this section. (c) finally, the function falls entirely in the section where hjk is negative : for the same reason, the integral is 0. Notice that it’s irrelevant what the value of k is for this analysis (since k will simply ‘shift’ the function right or left into another power of 2 subdivision of the unit interval : the reasoning does not change. Convince yourself of this before proceeding !)
Now, if j = j’ and k, k’ are different : this means that both functions are just as ‘wide’, but they fall in completely disjoint intervals (in other words, when one is non-zero, we’re guaranteed the other to be 0 and viceversa). Clearly, since one of the terms is 0, their inner product is also 0.
What we’ve proven above is that these functions are valid candidates for a basis for the space L2(R) : in other words, it is possible to represent any function in this space as a linear combination of these functions. To make the analysis complete we also have to prove
2). Normality :
We’d like to make the ‘norm’ of any hjk function 1 : the norm is defined as
![]()
![]()
The second step in the derivation above follows trivially from a change of variable. The third step follows from the fact that the square of the Haar function is 1 all over its domain [0,1] => the integral is also 1.
With these new results, the formal definition for the Haar basis of L2(R) becomes
![]()
2.3 Haar Coefficients and the Scaling Function
A function f(x) can be represented in terms of the Haar basis as follows :
![]()
The coefficients djk are called the Haar Wavelet
coefficients (and they’re what we’ll try to compute
later on : they are the actual wavelet) : ![]() . Notice
how we can ‘choose’ to represent the function at
various ‘detail’ levels :
. Notice
how we can ‘choose’ to represent the function at
various ‘detail’ levels :
·
at detail level 1, the
function is approximated ‘coarsely’ as ![]()
·
at detail level
2,![]()
Definition (Scaling Function) :
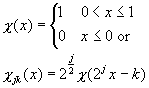
It’s easy to check that the ‘norm’ of Xjk is 1 (hence the need for the factor 2j/2 in front of it).
Since working with an actual (continuous) function f(x) is hard, we’d like to consider a set of ‘sample’ values taken from the function, to which we’d apply the Haar ‘algorithm’. Let’s call these sample points sjk (they basically become the ‘average’ value of the given function over adjacent intervals) :
![]()
We’re only looking at the integral of the function f over the interval [2-jk, 2-j(k+1)] : this is because the function Xjk has a non trivial value over that interval. Notice, as well, that the integral is scaled down by the factor 2j/2 in the expression of Xjk, which happens to be exactly the length of that interval. The Scaling Function bears its name from the fact that it ‘scales’ the function f(x) over a given interval and allows us to consider the ‘average’ of the function over that interval.
Review :
![]() : Haar
coefficients,
: Haar
coefficients, ![]()
![]() : Sampled
values of f(x),
: Sampled
values of f(x), ![]()
2.4 Recursive Algorithm for Computing Haar coefficients
Let’s compute sj,2k - sj,2k+1. This quantity is the difference between two adjacent sample values of the function we’re analyzing, on a given ‘detail’ level (in this case, level ‘j’). The reason we want to do this is because we want to see what is the relationship between the Haar coefficients and the actual sampled values of the function we’re analyzing.
Remember that the Haar coefficients are inner products between the actual function and the Haar functions. If we can establish a relationship between the Haar coefficients and the sampled values, we can in fact compute the Haar coefficients without having a function to work with ! In other words, given a set of point values, we can figure out the Haar coefficients without needing the function that generated those points. This is the process of ‘discretizing’ the wavelet transform (we’re working with a discrete set of points as opposed to an entire continuous function).
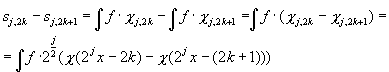
Let’s compute the difference of the X functions explicitly :
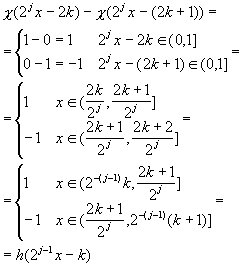
And now for the finale :
![]()
To summarize, we have the
relationship : ![]()
What does this really mean ? It means that once we compute the (sampled) values of the function on the ‘next’ level, we have the values of the Haar coefficients on the ‘previous’ level. One other way to look at this is to consider sjk to be the time average of f on the kth time interval of length 2-j; djk represent the variation of the average time signal on two consecutive signals.
The above relationship suggests the following recursive algorithm :
· start at given level j, with 2j sample values.
· compute the dj-1,k coefficients on level j-1. Notice that since we’re doing this pairwise, the number of d coefficients on level ‘j-1’ will be 2j-1.
· compute the sample values on level ‘j-1’ (by simply averaging them). Again, we’ll have 2j-1 sample values on level ‘j-1’
· recurse the process
At this point, you might want to read section 3 for an example of how the above process works.
2.5 Multiresolution Analysis
3. Algorithms and Visualization
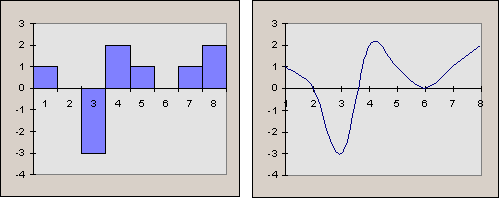
Here’s the Visual Basic code that will recursively compute the djk Haar coefficients for a given data set. The code should be verystraightforward and easy to understand. We start with the data (1, 0, -3, 2, 1, 0, 1, 2) on the first row of the spread sheet, in columns 1 through 8.
|
1 |
0 |
-3 |
2 |
1 |
0 |
1 |
2 |
|
The data series |
Level 3 (original) |
|
1 |
-1 |
1 |
3 |
1 |
-5 |
1 |
-1 |
|
/Sqrt(2) |
Level 2 |
|
0 |
4 |
2 |
-2 |
|
|
|
|
|
/2 |
Level 1 |
|
4 |
-4 |
|
|
|
|
|
|
|
/(2 * Sqrt(2)) |
Level 0 |
Notice that the relevant coefficients (djk) always lie in the second half of each row (the cells with thin outline). Each second half represents the ‘details’ in the data in the level above it (while the first half represents the ‘averages’ in the data in the previous level). The first entry on Level 0 is an average of the entire data set. Also note that the data computed in each level should be divided by the appropriate power of Sqrt(2) (see the formulas in the previous section).
'Macro to compute wavelet coefficients for a given sequence
'Razvan Surdulescu : Summer 1996
Sub ComputeWavelet(ByVal StartNdx As Integer, ByVal EndNdx As Integer, ByVal Level As Integer)
Dim Length As Integer
Dim X As Integer
Dim Y As Integer
'Base case : the length of the sequence given is 1 (2 elements in the sequence)
If (EndNdx - StartNdx = 1) Then
With ThisWorkbook.Worksheets(1)
'fill in averages
.Cells(Level + 1, StartNdx) = (.Cells(Level, StartNdx) + .Cells(Level, EndNdx))
'fill in details
.Cells(Level + 1, EndNdx) = (.Cells(Level, StartNdx) - .Cells(Level, EndNdx))
End With
Exit Sub
End If
'Length of the current sequence we're dealing with
Length = (EndNdx - StartNdx + 1)
'Fill in the sums and differences for the current sequence
For X = StartNdx To EndNdx Step 2
Y = StartNdx + (X - StartNdx) / 2
With ThisWorkbook.Worksheets(1)
'fill in averages
.Cells(Level + 1, Y) = (.Cells(Level, X) + .Cells(Level, X + 1))
'fill in details
.Cells(Level + 1, Y + Length / 2) = (.Cells(Level, X) - .Cells(Level, X + 1))
End With
Next X
'Call recursively for the next stage : note how we only need to consider
'half the data set at each stage
ComputeWavelet StartNdx, StartNdx + Length / 2 - 1, Level + 1
End Sub
Sub Main()
'Series starts at column 1, goes to column 8, and sits on row 1
'(the row value is also the depth level of the computation)
ComputeWavelet 1, 8, 1
End Sub
Things to notice :
· the size of the wavelet coefficients vector is the same as the size of the initial input
· the amount of time it takes to compute the wavelet coefficients is linear in the size of the input (read the code and convince yourself of this !)
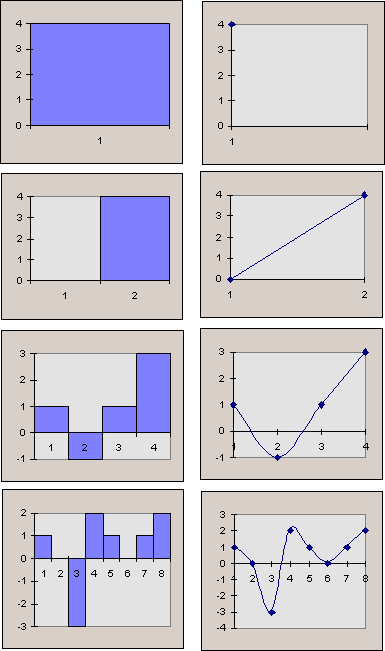
Now consider the reversed process. Take a look at the graphs below to see how the original data segment is being reconstructed from the wavelet coefficients :
|
4 |
-4 |
|
|
|
|
|
|
|
/(2 * Sqrt(2)) |
Level 0 |
|
0 |
4 |
2 |
-2 |
|
|
|
|
|
/2 |
Level 1 |
|
1 |
-1 |
1 |
3 |
1 |
-5 |
1 |
-1 |
|
/Sqrt(2) |
Level 2 |
|
1 |
0 |
-3 |
2 |
1 |
0 |
1 |
2 |
|
The data series |
Level 3 (original) |
'Macro to reconstruct graph from wavelet coefficients
'Razvan Surdulescu : Summer 1996
Sub ReconstructGraph(ByVal StartNdx As Integer, ByVal EndNdx As Integer, ByVal Level As Integer)
Dim Length As Integer
Dim X As Integer
Dim Y As Integer
'Length of the current sequence we're dealing with
Length = (EndNdx - StartNdx + 1)
'Base case : the length of the sequence given is 16
'We only have enough data to recover a sequence of length 8
If (Length = 16) Then Exit Sub
'Fill in the averages for the current level
For X = StartNdx To StartNdx + (Length / 2) - 1
Y = StartNdx + (X - StartNdx) * 2
With ThisWorkbook.Worksheets(2)
'fill in averages
.Cells(Level + 1, Y) = (.Cells(Level, X) + .Cells(Level, X + Length / 2)) / 2
.Cells(Level + 1, Y + 1) = (.Cells(Level, X) - .Cells(Level, X + Length / 2)) / 2
End With
Next X
'Call recursively for the next stage
ReconstructGraph StartNdx, EndNdx + Length, Level + 1
End Sub
Sub Main2()
'Series starts at column 1, goes to column 2, and sits in row 1
'(the row value is also related to the depth level of the computation)
ReconstructGraph 1, 2, 1
End Sub
4. Thresholding Techniques
5. Lifting
6. Application : Fast Multiresolution Image Querying
7. Bibliography :
[1] Fast Multiresolution Image Querying, {Charles E. Jacobs, Adam Finkelstein, David H. Salesin}, Department of Computer Science and Engineering, University of Washington. SigGraph ’96, Wavelets in Computer Graphics Course #13, pages 119-129.
[2] Building Your Own Wavelets at Home, {Wim Sweldens, Peter Shroder} SigGraph ’96, Wavelets in Computer Graphics Course #13, pages 17-84.
[3] An Introduction to Wavelets, {Amara Graps}, IEEE Computational Science and Engineering, Summer 1995, vol. 2, num. 2,
[4] Wavelets for Kids : A Tutorial Introduction, {Brani Vidakovic, Peter Muller}, Duke University
[5] The Xwpl system Reference Manual (for version 1.3 of Xwpl) {Fazal Majid (majid@math.yale.edu), Ronald R. Coifman, M. Victor Wickerhauser}
[6] Discrete Wavelet Transforms : Theory and Implementation {Tim Edwards (tim@sinh.stanford.edu)}, Stanford University, September 1991
[7] Wavelets : Mathematics and Applications {John J. Benedetto, Michael W. Frazier}, CRC Press, 1994