Figure 1-10
{{Maybe start rest of this section should be separate ch. 2 on URLs?, and then start following with: In ch. 1, saw how URLs for ISBN and UPS packages....}}
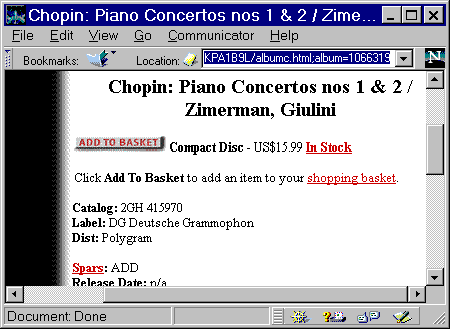
The same thing works for music CDs at the Tower Records web site (see Figure 1-10):
Chopin, Piano Concertos Nos. 1 & 2 (Zimerman, Giulini)
Chopin, <a href="http://www.towerrecords.com/prd.i/xt/tower/0L/ shopper.guest;__album=1066319;goto=albumc.html">Piano Concertos Nos. 1 & 2</A> (Zimerman, Giulini)
Figure 1-10
{{Movies at www.reel.com??}}
Nor is this ability to globally address specific items on the web limited to physical objects like books, packages, and CDs. To anticipate an example we'll be looking at in more detail later, there are several sites on the web that provide "current" (20 minute delay) stock prices.
{{MSFT (Yahoo, SecAPL); can look up symbols e.g. http://quote.yahoo.com/lookup?search=xxxx, or http://www-cgi.cnnfn.com/cgi-bin/researchit/company-search.cgi?text=xxxxxx; http://www.secapl.com/cgi-bin/lookup?tick=magellan&universe=MUTUAL; mutual funds? (e.g., http://quote.yahoo.com/quotes?symbols=FMAGX&detailed=t; from Morningstar; SecAPL has links to web resources, including from EDGAR Dissemination Project: http://www.secapl.com/cgi-bin/edgarlink?'FMAGX'); can do several symbols at once, e.g.; http://qs.cnnfn.com/cgi-bin/stockquote?symbols=msft+nscp}}
You can go to a form at one of these sites and type in the NASDAQ or NYSE symbol for a particular company, but if you do this often for the same set of companies or, more important, if you need to incorporate this capability into an application you're building, you can link directly to that company's current stock price:
Microsoft (MSFT) (from Yahoo!)
<A HREF="http://quote.yahoo.com/quotes?SYMBOLS=msft&detailed=t"> Microsoft (MSFT)</A> (from Yahoo!)
Netscape (NSCP) (from CheckFree Investment Services Quote Server; formerly Security APL)
<A HREF="http://qs.secapl.com/cgi-bin/qs?tick=NSCP">Netscape (NSCP)</A> (from CheckFree Investment Services Quote Server; formerly Security APL)
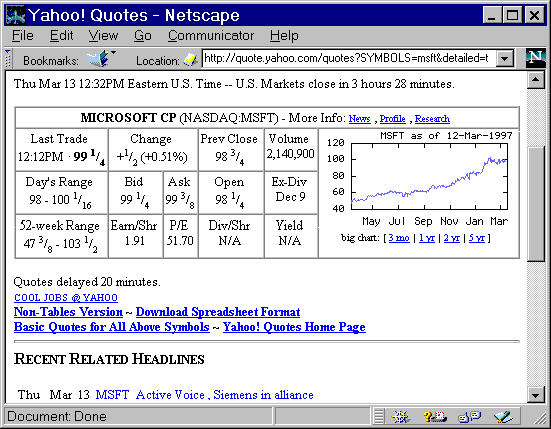
Figure 1-11
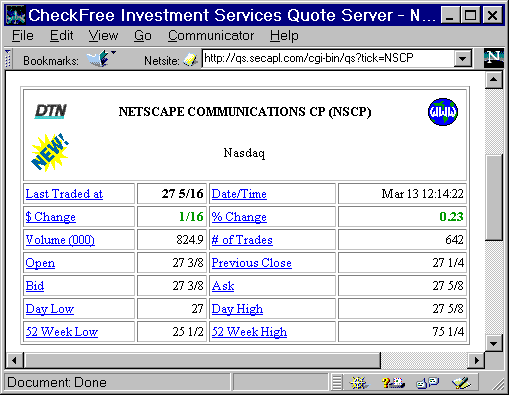
Figure 1-12
Again, the irregularity here is obvious -- Yahoo! (see Figure 1-11) wants "symbols=", whereas the CheckFree Investment Services Quote Server (see Figure 1-12) requires that the symbol be prefaced with "tick=" -- but the key point is that URLs often can serve as handles by which resources on the web can be grasped. Information on the web is not just something you find by "surfing"; once found, its address can be saved away as a handle for reuse by other applications. That URLs are handles to web resources also means that command-line tools can easily be built to perform actions on the web; see the "avsubmit" example later in this chapter.
You may be wondering about the legal implications of this intellectual-property reuse. Is it "fair use"? We'll get into that later in this chapter (see sidebar below); for now, simply note that we're just referring to these other sites with <A HREF>; this is similar to a footnote, which is unquestionably legal. This question is a lot more complicated when you're talking about building on the intellectual property of others with something like <IMG SRC> or <FRAME SRC> or <FORM ACTION>. {{See later about legal dispute over TotalNews use of frames.}}
So far, our examples have all involved something in which the outside world imposes some regularity: books have ISBN numbers, packages have tracking numbers, publicly-traded companies have symbols. The next example is fairly different: anyone who has ever posted a Usenet message since March 1995 has an address on the web, courtesy of DejaNews, containing a list of links to all their messages (DejaNews says their current database is 175 gigabytes; they say they eventually want to include every Usenet message going back to 1979). For instance, here is a URL (actually, a rather naive URL; see the sidebar below) which represents a list of news messages posted by a friend of mine, Richard Smith, president of Phar Lap Software (see Figure 1-13):
<A HREF="http://xp5.dejanews.com/profile.xp? author=%22Richard%20M.%20Smith%22%20%3crms@pharlap.com%3e"> What's Richard been up to?</A>

Figure 1-13
The strange-looking things like %22 and %20 are merely characters such as quotation marks and spaces. A URL can't include such characters, so they are "escaped". The DejaNews server will decode the second part of the URL as:
?author="Richard M. Smith" <rms@pharlap.com>
It's useful to include both the author's name and email address, particularly because many news posters have uninformative email addresses such as 72143.2726@compuserve.com.
Naive URL Re-UseThere's one problem with the URL shown here. The source for another page at DejaNews (unfortunately, not the one from which this URL came) contains the following note:
DO NOT USE THIS FORM ACTION AS-IS! Replace the explicit machine name (e.g. xp1.dejanews.com) by "search.dejanews.com". This is rotated between many servers to give the best turn-around on queries.Thus, the URL should really be: http://search.dejanews.com/profile.xp? author=%22Richard%20M.%20Smith%22%20%3crms@pharlap.com%3e This illustrates a common problem on the web: Someone finds something interesting, so they just grab the URL using something like the "Copy Link Location" option in Netscape Navigator, and then bookmark it, email it to a friend, or reuse it in a web page. This naive URL use often leads to wrong results of one sort or another. In the current example, it will produce an unnecessary strain on the xp5.dejanews.com machine. In other examples, it will take someone to the wrong page. Often you'll see something like "see the articles about our new product at http://www.zdnet.com/home/filters/news.html and http://www.techweb.com/search/advsearch.html". But these URLs represent online news magazines that change several times a day. Fortunately, CMP's TechWeb puts a note like the the following at the bottom of its news articles:
You can reach this article directly:Unfortunately, many sites whose visible URLs represent transient content fail to provide such direct links to the permanent versions of the content. This is similarly a problem at many sites that employ frames: the visible URL merely represents the web page containing the top-level <FRAMESET> tag. Figure 1-8 is a good example: the "https://" URL address of the second frame is nowhere to be seen. Most likely, someone grabbing this URL for reuse in fact wants the URL now showing in one of the frames. (On the other hand, that URL is probably intended to be viewed in the context of the frameset, so simply grabbing the frame's URL might also lead to incorrect results: authors of web pages can easily solve this problem with a small amount of JavaScript, shown later in this chapter.) {{On URL problems created by frames, see http://www.useit.com/alertbox/9612.html: Why Frames Suck (Most of the Time) by Jakob Nielsen; counts frames as one of his top 10 web design mistakes: "Even worse, URLs stop working: the addressing information shown at the top of the browser no longer constitutes a complete specification of the information shown in the window. If an author copies the URL in order to include it as a hypertext anchor in one of his or her own pages then that anchor will not lead readers to the desired view but to the initial state of the frameset. Similarly, if a user decides to send an email message to a friend with the recommendation to check out a page, then copying the URL from the browser will not work if frames are used since the URL points to the frameset and not to the current view (with the information of interest to the friend). Given that social filtering is one of the most powerful mechanisms for information discovery on the Internet, it is an utter disaster to disable the URL as an addressing mechanism."}} This frequent mismatch, between the URL seen in a browser location bar, and the actual URL you need to reuse, is not so much a problem with URLs themselves, as with the way in which URLs are commonly "discovered" (see the discussion below of "educated guesses"). |
Most of our example URLs have contained a question mark (?). As Tim Berners-Lee notes in his 1994 paper on "Universal Resource Identifiers in WWW" (http://info.cern.ch/hypertext/WWW/Addressing/URL/URI_Overview.html), ? marks the boundary between the URL of a "queryable object, and a set of words used to express a query on that object." The entire URL then "stands for the object which results from the query being applied to the original object."
What does this mean in the context of a static web page? Nothing, of course. The point, rather, is that many web "pages" are not pages at all, but queryable objects: that is, active computational resources. (Actually, now that HTML pages can include JavaScript, even a standalone web page can be a queryable object: we'll get to this soon.) In the case of DejaNews, "profile.xp" is obviously some sort of program -- at one point, it was a Tcl script named "dnauthor-profile.tcl" -- that's run at DejaNews whenever you send it a user-profile query. Simply clicking on a hyperlink like that shown above generates such a query.
In other words, URLs have nothing to do with files or filenames as such. A URL might indicate a filename, but then again it often indicates the result of some database query or other computational process. This can be true even if there's no ? in the URL.
Unfortunately, there is widespread misunderstanding about this. Tim Berners-Lee's 1994 paper explicitly notes that the / used for structure hierarchy in a URL resembles a filename only in a purely coincidental way, and that URLs should not be viewed as filenames. Even if the URL does happen to correspond to an actual file located on the disk of a machine running a web server, there is no necessary correlation between the URL and the filename in the server's native operating system: most web servers provide "document mapping," URL "redirection," or some type of "alias" facility.
According to the tech support group for ORA's WebSite server, the mapping of URLs to objects is probably the most-frequently misunderstood concept among their users. Yet only a moment's reflection shows that a URL such as http://www.ups.com contains no file-system information: the web server must be using the empty path (or a path such as "/") as a hint to fetch a file such as "index.html" or perhaps to start a CGI program. In other words, a web server is itself a sort of database query engine, which maps queries to the data that it sends back.
{{Details from Bob Denny might make good sidebar?:
(1) When a user asks for a URL such as http://www.ups.com, which has no pathname information, though maybe with a trailing '/' at the end, how does the server (WebSite or web servers generally) resolve this into a web page such as index.html? Is the mapping of '/' into index.html automatic, or is it a user setting, or what?
There are 2 questions there. First, the "/" URL is translated to a physical disk location via the "/" mapping (document map). Secondly, once the server discovers that the target is a directory (and not a document) it does the following:
(a) Look for a file that matches "index.*" (this is the default setting, it can be changed on the Dir Listing tab of the property sheet, Special documents, Default).
(b) If it cannot find something that matches, it generates an automatic directory listing HTML page, with whatever frills are set up.
(2) Is there some way to tell a web server to turn '/' into a CGI program? And/or someway to alias an .html file into output from a CGI?
Yes, WebSite has "server-side content types" (SSCT), which can be identified by their major type of "wwwserver". For example files ending in .wcgi are typed "wwwserver/wincgi". This SSCT says "this is not a document, run it using Windows CGI".
Combining the two, you place a Windows CGI executable called "index.wcgi" into the "/"-mapped directory, and you have a CGI program that runs when the root/home page is the target. index.wcgi matches index.*, right? Just make sure that there aren't any OTHER index.* files (index.bak, index.html, etc.) in the directory or the results are unpredictable.}}
We've seen that, in a URL such as http://hostname/path, the "/path" portion isn't necessarily a file's pathname. Similarly, the "hostname" portion is less hard-wired than it appears: a web client uses this hostname to perform a lookup (generally via gethostbyname() socket call, or the WSAAsyncGetHostByName() WinSock call) from a DNS name server, from which it gets an IP address. And it is well known that on the Internet, the route from your machine to this other machine is not hard-wired either (see the discussion of traceroute later in this chapter). The connection between a URL, and the data sent back in response to that URL, is quite indirect.
{{Maybe traceroute goes here? Traceroute shows path (idea/myth that Internet built to survive nuclear war???); contrast UUCP hard-wired paths; any servers support HTTP TRACE? See Ray's article in Web Apps (March-April 1997); http://www.internetweather.com/; http://www3.mids.org/weather/; http://ext2.mfsdatanet.com/MAE/west.mfs.overlay.html; http://www.pacbell.com/products/business/fastrak/networking/nap/stats/}}
A URL, then, is not a "pointer" to a file, nor a "pointer" to anything else, if by the term "pointer" we mean something that contains exact location information. Instead, a URL is what is sometimes called a handle: think of it as a "claim check" or "laundry ticket." It has some markings, sufficient to access your stuff, but no one except the server really tries to understand these markings. A client passes the handle to a server, but it doesn't otherwise do much with it.
That's the idea, anyway. In fact, a client has to understand a URL well enough to extract the hostname from it, use DNS to turn the hostname into an IP address, and then send the remainder of the URL to this address.
In addition, the fact is that browsers often do try to interpret the pathname portion of URLs, by using file extensions (such as ".html" or ".gif") as indications of how to display the data that comes back. Browsers should be relying instead on the "Content-type" HTTP header that servers provide for the returned data, but apparently many of them instead extract file extensions from URLs. This is why (to anticipate a later example) CGI programs that produce images generally have a ".gif" extension -- even if it's a perl script, whose proper extension on the server would be ".pl", and which provides a "Content-type: image/gif" HTTP header. Of course, with protocols other than HTTP, such as ftp:// or file:// (see below), which don't return a "Content-type", the browser has no choice but to intuit what it can from the URL.
Another important exception to the "URL is a handle" rule is that a user might sometimes make an "educated guess" about a URL. Once you know that book information can be retrieved from a certain online bookstore using an ISBN number, you might tell a friend about a book you think they simply must buy and read by sending them a URL that you've constructed yourself, using the ISBN number on the back of the book, together with what seems to be the rule for constructing URLs at this site. Why bothering entering the book's name in a search form, if you can predict what the URL will be? If a book has the ISBN number 0-684-80079-9, it seems obvious by now that its URL at amazon.com will be http://www.amazon.com/exec/obidos/ISBN=0684800799. Is this equivalent to forging one of those "claim checks" or "laundry tickets" we were just talking about? Hard to say.
{{http://www.secapl.com/secapl/quoteserver/ticks.html, "Some Guidelines for Ticker Symbols" gives rules. For example: "To get a quote on preferred stocks you need to add the letter '1' immediately following the symbol (no space) and sometimes the letter for the preferred issue. For example 'Bank of America Preferred F' symbol is 'BAC1F'. Preferred are usually only traded in New York but sometimes you can append the city code and come up with a valid symbol, for example 'CHI1.B' is the preferred stock for Furrs Bishop on the Boston exchange only (CHI1 is the composite symbol)." Note the "sometimes ... come up with a valid symbol".}}
{{Tim: need book to document these web-based APIs!!}}
Some sites might actually document their URL-construction rules: the "Linking Instructions" at http://www.books.com/scripts/showform.exe?file~links.html is an excellent example.
{{amazon.com not give URL format, but does have "search language": http://www.amazon.com/exec/obidos/subst/expert-query.html, http://www.amazon.com/exec/obidos/subst/expert-mode-help.html. Can rely on this in programs like isbn2price??}}
But linking to other sites might involve making an educated guess: in Figure 1-9, I simply derived the tracknum= interface to tracking.cgi from the form that UPS provides at tracking.html. Chapter 4, "Snarfing Forms," has many more examples of how one goes about this, but it's important to realize that the site could always change its underface out from under any software of yours that relies on it. Well, that's true of documented URL interfaces too. The whole area of URL "discovery" is still fairly primitive.
{{Jakob Nielsen, http://www.useit.com/alertbox/9605.html on top 10 web design mistakes: "4. Complex URLs. Even though machine-level addressing like the URL should never have been exposed in the user interface, it is there and we have found that users actually try to decode the URLs of pages to infer the structure of web sites. Users do this because of the horrifying lack of support for navigation and sense of location in current web browsers. Thus, a URL should contain human-readable directory and file names that reflect the nature of the information space. Also, users sometimes need to type in a URL, so try to minimize the risk of typos by using short names with all lower-case characters and no special characters (many people don't know how to type a ~)." See later point about CRAYOLA; Tom Brokaw quote.}} Okay, so URLs aren't files. So what? Why is this so important? A 1994 paper on "Interactive Information Services Using World-Wide Web Hypertext" by Steve Putz at Xerox PARC (Palo Alto Research Center; see http://www.parc.xerox.com/istl/projects/www94/iisuwwwh.html) provides an excellent answer:
"... the HTML hypertext format and the HTTP retrieval protocol can provide more than simple document browsing and retrieval. With additional server software, the same protocol and generic browsers can allow access to may kinds of interactive information sources while providing customized user interfaces." "Hypertext links are used not only for navigation, but also for setting search and presentation parameters. In these applications the HTML format and the HTTP protocol are used like a user interface tool kit to provide not only document retrieval but a complete custom user interface specialized for the application."Interactive information sources, customized user interfaces, user interface tool kit: this all sounds like software! Indeed, the sample web site described in this 1994 paper, the Xerox Map Viewer (http://mapweb.parc.xerox.com/map), is clearly not a static document, but a full-fledged piece of software. Yet it's all done using HTML, HTTP, and the perl scripting language.
There's a programmer's interface to this software, an "API" (application programming interface) as they're often called: the Map Viewer API consists entirely of URLs (see the "URL format" description at http://www.parc.xerox.com/istl/projects/www94/mapviewer.html#URLFORMAT). The URL format is simply http://mapweb.parc.xerox.com/map/option=value/.../option=value, where the options specify latitude (south is negative), longitude (west is negative), the width and height of the map (expressed in degress), and other rendering attributes, described at http://www.parc.xerox.com/istl/projects/www94/mapviewer-options.html. For example, the following URL produces a map of the Hawaiian islands:
http://mapweb.parc.xerox.com/map/lat=21.34/lon=-157.97/wd=9.0/ht=4.5
This URL interface really is an API: other software can be built on top of it. The U.S. Geological Survey (http://www-nmd.usgs.gov/www/gnis/gnisform.html), for instance, where you can search for geographical features by name, has an option to use the Xerox PARC map server. A search for Hannibal, Missouri (Mark Twain's birthplace; also known as "Stavely's Landing"*) is as simple as:
Footnote: *See the wonderful story behind this in Twain's Life on the Mississippi, chapter 55, which is of course on the web: http://www.teachersoft.com/Library/lit/twain/life/chapt55.htm.
http://mapping.usgs.gov:8888/gnis/owa/gnisquery?f_name=hannibal&f_state=mo&tab=y
After clicking some more links and checkboxes, you arrive at:
This page in turn contains images produced by "direct map request" from the Xerox PARC map server, such as:
Thus, a piece of software at mapping.usgs.gov (running NCSA/1.5; presumably in Washington DC) is directly incorporating images generated "on the fly" by a program running at mapweb.parc.xerox.com (running plexus/2.2.1; in Palo Alto CA). PC software developers might ponder this for a few minutes: could you have done anything remotely like this using the pre-web Windows API?
Map Mania: Latitude/Longitude URLsThe interface to the Xerox PARC Map Viewer requires latitude and longitude. And its maps unfortunately lack any sort of labels. The US Geological Survey site shows that a gazeteer front-end can be built to turn a query such as "f_name=Hannibal&f_state=MO" into the appropriate "/lat=39.7089/lon=-91.3886/etc." incantation for the Xerox PARC server.The next obvious question is how to get a map, with labels, and maybe with driving instructions too. There are numerous services like this on the web, and generally these mapping services can be driven with URLs. Not all are as well-documented as the Xerox PARC server, but these map services all provide excellent examples of using the web as a software platform. According to its FAQ, the name server at the US Census Bureau http://www.census.gov/cgi-bin/gazetteer generates 25-30 thousand maps per day. While it doesn't explicitly document its URL format, it does document a form for inclusion in other web pages ( http://ftp.census.gov/tiger/tms/gazetteer/interface.html). The form's variables include "city", "state", and "zip", so you can access the server with URLs such as:
http://www.census.gov/cgi-bin/gazetteer?zip=95404 These will take you to a page which has the corresponding latitude and longitude, which you could then plug into the Xerox PARC server. In chapter XXX, we'll see how to write a program (somewhat like what the US Geological Survey is doing) that extracts the latitude and longitude from this page, and then creates an appropriate URL to retrieve an image from the Xerox server. But the Census Bureau page also has direct links to the Census Bureau's own "Tiger Mapping Service" (TMS), such as: The TMS "Direct Map Request" interface is documented (see http://tiger.census.gov/instruct.html): The TMS Map Browser is not the only way of accessing TMS-generated maps; it is only an example application. By using the syntax below, anyone can request maps directly via a URL. This makes it possible to include TMS maps in your own documents, or even your own interactive mapping applications, because a "live" TMS map addressed using the URL described below can be used in exactly the same manner as a static GIF image (i.e., in a <IMG> element).Basically, a map can be requested directly from TMS by using the URL format http://tiger.census.gov/cgi-bin/mapgen?parameter&...¶meter where the parameters can be lat, lon, wid, ht, and so on. It's worth noting that the maps produced by this US government site are all public domain. So much for government sites: what about commercial mapping? There are several superb Yellow Pages services on the web that provide maps. The Yahoo! Yellow Pages provide two services, MapIt! and DriveIt!, which for example can be told to generate a map showing how to get from San Francisco to the O'Reilly & Associates offices in Sebastopol CA. Check out the following 400-byte "URL from hell": These services are provided for Yahoo by Vicinty MapBlast!, whose own site has a form that will construct HTML code that you can incorporate into your own web pages. Enter some location information into the form at http://www.vicinity.com/yt.hm?CMD=FILL&FAM=mapblast&SEC=start, and you'll get back some code such as: <!--Cut below this line-----------------------------------------> <!--Free map from Vicinity--> <A HREF="http://www.vicinity.com/yt.hm?FAM=mapblast&MA=1& \ GC=X:-122.8179|Y:38.40298|LT:38.40298|LN:-122.8179|LS:20000| \ c:Sebastopol|s:CA|z:95472&IC=38.40298:-122.8179:5:O'Reilly+ \ %26+Associates&GAD2=103+Morris+St&GAD3=Sebastopol%2c+CA& \ STYLE=mbMidday&LV=3&CMD=MAP&SEC=blast"> <IMG BORDER=3 WIDTH=425 HEIGHT=250 SRC=/gif?& \ CT=38.40298:-122.8179:20000&IC=38.40298:-122.8179:5:O'Reilly+ \ %26+Associates&FAM=mapblast&STYLE=mbMidday></A> <center>Click on the map to browse</center> <!--End of Vicinity Map--> <!--Cut above this line----------------------------------------->You can even email a map to someone else ("Directions to the party Saturday night at our house!"), or simply save it to your own web site. The key is using the URL as a "handle" to the map: Your map remains dynamic and interactive (customizable) after you have saved it, added it to your website, or e-mailed it. That�s because "saving" the map actually saves the map�s HTML code to the Vicinity MapBlast! server. To make further changes, click anywhere on the map. Be sure to save your changes back to your website or they will be lost.Another good map-enabled Yellow Pages with maps is Zip2. Its option to use Java to "drill down" and zoom around the map is particularly cool. Starting, for example, at a map of the entire US: You can then zero in to a very specific address in just a few clicks: It's quite amusing to look at all this amazingly dynamic software, built with simple web standards, and then listen to Microsoft's slogan "Activate the Internet" -- as if everyone was waiting around, building static web pages, until ActiveX came along. Windows developers, please note that none of the cool applications described here use ActiveX. You probably don't need ActiveX (or Java, for that matter) for 90% of what you may think you need it for. These serious government and commercial applications have been built using common Internet standards: HTML, HTTP, CGI, and as we've seen, very heavy use of URLs. Okay, the Zip2 Yellow Pages has an option to use Java, but this can easily be disabled -- though even a Java pessimist like me does have to admit that Java definitely improves this application.
|
{{Rough from here on!}}
If Java improves it, maybe ActiveX, VRML, etc. would too. How much? Worth extra complexity? 90/10 rule.
http://www6.nttlabs.com/HyperNews/get/PAPER130.html: Maps Alive: Viewing Geospatial Information on the WWW, Michael Potmesil (Bell Laboratories, Lucent Technologies): "Much information available on the WWW, such as weather reports, home pages of National Parks, VRML models of cities, home pages of Holiday Inn hotels, Yellow and White Page directory listings or traffic and news reports are better visualized when displayed directly or via an anchor on top of 2D maps or in a full 3D environment." "For the time being, we ignore here all copyright issues since this is being tried only for research purposes." Mentions www.mapquest.com (didn't work well), BigBook 3D (VRML: http://vrml.bigbook.com/showpage.cgi?page=bb3d_entry; requires Netscape Live3D plug-in; see http://home.netscape.com/comprod/products/navigator/live3d/; nothing really worked).
Input to programs can be treated as though it were part of an address. This means software -- certain types of software, anyway -- can be "driven" with URLs. It's helpful to think of URLs as "command lines." {{Long and lat in URLs from hell! Long/lat quite literally "mapped" into web address space!! Web as space: see WebReview http://www.webreview.com/97/04/04/addict/index.html on SemioMap, HistoryTree, etc.: "Mapping Chaos: Tools for Visualizing Web Content"}}.
{{Dan Connolly on URLs == "object references" goes here instead of in distribution computation section?}}
Since mappers are full-scale apps (commercial in case Yellow Pages), with complicated interfaces, a simple, trivial, service might make clearer. Further shows that even standalone HTML files, not residing on an HTTP server, can now behave like software. As shown in Figure 1-sqrt {{renumber later}}, sqrt.html is a program that accepts a number on its "command line" (the query portion of the URL), and returns the number's square root.
{{Need to redo all this sqrt.html stuff: needs to be better example of doc that return answer to query. Should use to show how document == program; old false division; Brad Cox, Superdistribution; but this problems (email bomb sidebar); problems with MS proposed "Active Streaming Format" (ASF), to include "audio, video, still images, events, URLs, HTML pages, script commands and executable programs"! Erase difference code and data. Back to self-modifying code, executable data, code/data equivalence, etc. Good development, I suppose, and makes sense technically, but are we ready for this?}}

Figure 1-sqrt: have to redo with <H1>
Figure 1-sqrt2 shows that, if sqrt.html is accessed without any parameters, the HTML program instead displays a form into which a user can enter a number. Pressing the submit button then generates the appropriate URL, such as "sqrt.html?144" or "sqrt.html?-1". The program displays its direct URL interface, along with a "live" example that the user can click.
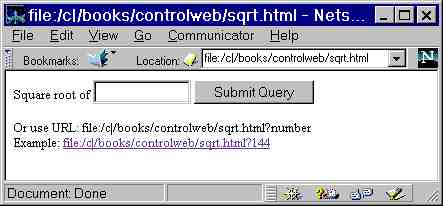
Figure 1-sqrt2
As shown below in Example 1-4, the source for sqrt.html uses JavaScript: unlike Java code, JavaScript can go right on a web page alongside HTML; it acts as an extension to HTML. JavaScript can also output HTML "on the fly"; notice, for example, how sqrt.html uses the document.write() function to create that live link to the sample URL. JavaScript can access the URL of the page that contains it; sqrt.html retrieves uses location.search to retrieve a query such as "?144", uses String.substring() to peel off the "?" (and possibly an "x=" prefix from the form), passes the result to Math.sqrt(), and finally to document.write().
<HTML>
<SCRIPT>
if (location.search)
{
// write(sqrt(substring(location.search)))
x = location.search.substring(1); // remove "?" from query
if (x.substring(0,2) == "x=")
x = x.substring(2); // remove "x=" if present
document.write("<H1>", Math.sqrt(x), "</H1>");
}
else
{
document.write('<FORM ACTION="', location, '" METHOD=GET>');
document.write('Square root of <INPUT TYPE=text SIZE=12 NAME=x> ');
document.write('<INPUT TYPE=submit>');
document.write('</FORM>');
// use Location object so can freely move or rename this file
document.write('Or use URL: ', location, '?number<BR>');
document.write('Example: ', '<A HREF="', location, '?144">');
document.write(location, '?144</A><BR>');
}
</SCRIPT>
</HTML>
So when I said earlier that ? means nothing in the context of a web
page, and is only for "queryable objects," that was an
oversimplification, because with JavaScript, which can make decisions
based on the query string, plain web pages are queryable objects too.
You might think that once we include JavaScript, we no longer have a
"plain" web page, but JavaScript really is just an extension to HTML,
even though syntactically is looks like Java or C. You might want to
view JavaScript as a large number of new HTML tags you've been given.
On the other hand, while Netscape strongly backs JavaScript, other
browsers don't support it, or don't support it properly. As one small
example, if sqrt.html is located on the local hard disk and accessed
via a file:// URL (see below), MSIE doesn't realize that ? can be
applied to the file: it looks on disk for a file named
"sqrt.html?144" or whatever, gives up, and then asks you to "Make
sure the path or Internet address is correct."{{MSIE does do the right thing if accessed via http:// protocol, presumably because not trying to extract filename portion of URL; just passes to server, not interpret; with file://, browser must interpret, and MSIE does so incorrectly: assumes that HTML can't be queryable -- which in keeping with MS's seemingly remarkably ignorant assumption that ActiveX is the only way to have dynamic web pages.}}
{{Except!! Said sqrt.html "returns" value. But can't get at that value e.g. from GETURL: just get back the script. Requires JS-enabled browser, so really displays, not "returns" (see later that returned HTML pages can be manip by program). So this really needs to be server-side JS (LiveWire): try with Netscape FastTrack 2.0 for Win95!}}
http://www.sonic.net/cgi-bin/undoc/sqrt.pl?144 -- show difference between this and JS-based sqrt.html, by looking at output with geturl:
C:\>geturl http://www.sonic.net/cgi-bin/undoc/sqrt.pl?3.999 http://www.sonic.net/cgi-bin/undoc/sqrt.pl?3.999 Connecting to 208.201.224.21 HTTP/1.0 200 Document follows Date: Tue, 01 Apr 1997 20:26:24 GMT Server: NCSA/1.5.2 Content-type: text/html <H1>1.99974998437305</H1>Also note different version of sqrt.pl, c:\httpd\cgi-bin\sqrt.pl, which uses cgi-lib.pl: after call ReadParse, can just access variables with $in("var")}. WOW! It doesn't get much easier than this!:
#!/usr/local/bin/perl
require "cgi-lib.pl";
print &PrintHeader;
if (&ReadParse) {
print "<h1>", sqrt($in{"x"}), "</h1>";
} else {
print '<form method=post><input type="submit">Data: <input name="x">';
}
For example: geturl http://localhost/cgi-bin/sqrt.pl?x=144Since geturl does -post (see chapter 5), can also do:
geturl -post x=144 http://localhost/cgi-bin/sqrt.pl
Hmm, worth pondering difference between these two. The -post one not really in "URL space", though as command line shows, not far from it. Could obviously build a "get to post" translator.
sqrt.pl creates almost infinite "URL space". Note one purpose of robot exclusion standard (see ch. 5) is to keep robots out of "infinite URL spaces in which robots could get trapped ('black holes')" (http://info.webcrawler.com/mak/projects/robots/eval.html).
The sqrt.html program doesn't provide a particularly worthwhile service, but it certainly does show that a self-contained HTML page can have a URL-based API. For a more practical example, see Phar Lap's debugger (http://smallest.pharlap.com/debug/dumpmem.htm?address=63970), described below.
Aside from demonstrating a tiny URL-based API, sqrt.html also has one very weird feature: once sqrt.html is placed on a server, every number whose square root one might want to check suddenly acquires an "address" on the web, just like those books and packages whose URLs we looked at earlier. For example: http://www.sonic.net/~undoc/book/sqrt.html?1234.56789. Each possible input to the sqrt() function has a unique URL.
{{sqrt just an example. For that matter, could use eval() (turns string into executable JS code) to map all JS expressions onto URL space:
<SCRIPT> document.write(eval(location.search.substring(1))); </SCRIPT>http://www.sonic.net/~undoc/book/eval.html?1+2*3/Math.sqrt(17.111)+Math.random()
{{Why not seem to work for eval.html?navigator.userAgent?}}
URLs provide space into which almost any computational problem can be mapped.
It sounds peculiar to put it this way, but actually, any program with a URL-based interface treats its input as part of the world-wide web address space. Even things with own "address space": maps, lat/long. The URL scheme makes it possible to map any sort of computational problem into web address space: an address for everything -- or, at the very least, everything can be presented as an address. Disparate types of resources -- not just documents, but also processes and devices -- can be made accessible as if they were part of a single, unified global file system: a big hard disk. With every file (as see from JS example) potentially a queryable object.
{{gopher:// example: TitleNet for books based on Gopher menu: gopher://gopher.infor.com/; e.g. gopher://ns1.infor.com:70/77/.bin/s_ti?hacker for books (from participating publishers: not many) with "hacker" in title; browser produces menu; Eric Raymond is gopher://ns1.infor.com:4100/1exec%3AR8005026-8006811-/.text/Main%3A/.bin/views}}
For example, getting back for a moment to my original example, (extended example?) my Unauthorized update page: ftp://ftp.ora.com/pub/examples/windows/win95.update/unauthw.html (can seamlessly integrate with http:// stuff; relative ftp:// URLs work too; note that .html extension on ftp://, browsers do right thing (must be looking at extension, because FTP not return MIME type! same with .gif! Said earlier, browser has to intuit from URL if protocol not return a "Content-type"); can have http:// alias; http:// can also seamlessly link to ftp:// that not .html, of course, e.g., my .c files updating book). Add all this to ex12.html: make sidebar with .gif with links to my ftp://
{{Following using SCRIPT stuff that not introducing until later??? This is for ftp:// discussion (see how ftp from my site flows into frame, etc.); didn't introduce JS frame until file://?? Also didn't show image button inside table/box until lmet.fr?}}
Change following to offer choice of bookstores, including lmet.fr?
<!-- ex12new.html -->
<FRAMESET FRAMEBORDER=no BORDER=0 FRAMESPACING=0 COLS=150,*>
<FRAME SRC="sidebar.html">
<FRAME SRC="http://www.ercb.com/ddj/1995/ddj.9504.html" NAME=fr2>
</FRAMESET>
<!-- sidebar.html -->
<SCRIPT>
if ((parent.frames.length == 0) || (parent.frames[1].name != "fr2"))
window.location = "ex14.html"
</SCRIPT>
<<!-- button: use single-column table to make box around image: button -->
<TABLE BORDER=3><TR><TD>
<A HREF="http://www.amazon.com/exec/obidos/ISBN=1568843054" TARGET=fr2>
<IMG SRC="http://db.idgbooks.com/images/smallcovers/1-56884-305-4.gif">
</A>
<A HREF="http://www.amazon.com/exec/obidos/ISBN=1568843054" TARGET=fr2>
Order it</A>
</TR></TABLE><P>
<A HREF="ftp://ftp.ora.com/pub/examples/windows/win95.update/unauthw.html"
TARGET=fr2>Updates</A><P>
<A HREF="http://www.byte.com/art/9503/sec6/art3.htm" TARGET=fr2>
<I>Byte</I> review</A><P>
<A HREF="http://www.ercb.com/ddj/1995/ddj.9504.html" TARGET=fr2>
<I>Dr. Dobb's</I> review</A><P>

ex14.html: <FRAMESET ROWS=20%,*> <FRAME SRC="ex15.html"> <FRAME SRC="file://c:\" NAME=fr2> </FRAMESET> ex15.html: <A HREF="file://c:\windows" TARGET=fr2>Your c:\windows directory</A> * <A HREF="file://c:\autoexec.bat" TARGET=fr2>your autoexec.bat</A> * <A HREF="file://c:\config.sys" TARGET=fr2>your config.sys</A><P>
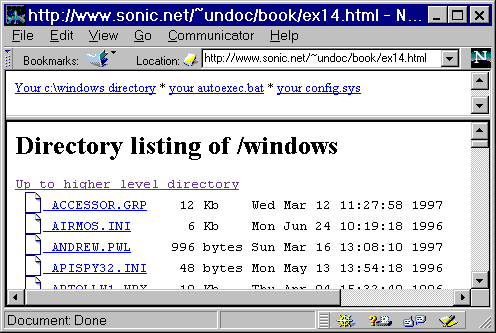
Obviously OS-specific. If reader not Windows machine, doesn't work. Can exclude non-Windows users with tiny piece of JS:
<SCRIPT>
// if HTTP User-Agent doesn't include "Win", e.g., "Mozilla/4.0b2 (Win95; I)"
if (navigator.userAgent.indexOf("Win") == -1)
{
document.write("Sorry, this only works on Windows machines");
// in 7 seconds, send them back to previous page they were on
window.setTimeout("window.history.back()", 7000);
}
</SCRIPT>
Solving a Problem with FramesWhat, incidentally, if someone loads ex15.html rather than ex14.html? This is a problem with frames: a page is often meant to be viewed in the context of a particular frameset, but readers may arrive at this page rather than at the frameset. For example, AltaVista would tell them that that the string "your config.sys" is located in ex15.html, and would present them with a hyperlink to that file, even though they should really load ex14.html. The TARGET=fr2 in ex15 won't work otherwise.This problem is easy to fix with (what else?) JavaScript. Here is a small piece of code, to be placed at the top of ex15.html, that will force-load ex14.html if the proper frameset isn't in place:
<SCRIPT> if ((parent.frames.length == 0) || (parent.frames[1].name != "fr2")) window.location = "ex14.html" </SCRIPT>{{Explain: HTML right in web page. Setting window.location will load designated page to replace current page. Test: if no frames, or if 2nd frame (frames[1]; numbered from 0) not named "fr2" (from ex14.html), then do it.}} While we're here, might as well add extra twist: what if first frame of ex14 could contain either ex15 or foobar? Still want to relocate to ex14, but with fr1 containing previous location (either ex15 or foobar). I asked David Flanagan, author of excellent JavaScript in a Nutshell, about this, and he suggested this: encode the desired contents of the second frame as a query string in the URL. That is, add the following to ex16.html (and similarly modify ex15.html): <SCRIPT> if ((parent.frames.length == 0) || (parent.frames[1].name != "fr2")) window.location = "ex14.html?ex16"; </SCRIPT>Then, back in ex14.html, use the search property of the Location object (location.search) to retrieve the query string portion of the URL. The search string will include "?", which must be stripped off with String.substring() function. Make the resulting name the SRC for first frame, rather than hardcoding "ex15.html". So ex14.html now looks like this:
<SCRIPT>
<!--
loc = (location.search) ? location.search.substring(1) : "ex15";
document.write('<FRAMESET ROWS=20%,*>');
document.write('<FRAME SRC="' + loc + '.html">');
document.write('<FRAME SRC="file://c:\" NAME=fr2>');
document.write('</FRAMESET>');
-->
</SCRIPT>
<NOSCRIPT>
<FRAMESET ROWS=20%,*>
<FRAME SRC="ex15.html">
<FRAME SRC="file://c:\" NAME=fr2>
</FRAMESET>
</NOSCRIPT>
As noted earlier, MSIE dislikes even having ? in location for .html
file when do file:// -- MS not quite understand that html page is
queryable object? This would be in keeping with their general
underestimation of capabilities of non-MS standards such as html.
Works when http:// protocol, because just peeling off pathname,
handing it to server? {{Don't repeat, don't snipe!}}
|
<FORM ACTION="mailto:andrew@ora.com" ENCTYPE="multipart/form-data" METHOD=POST> <INPUT TYPE=file NAME=file VALUE="c:\autoexec.bat"> <INPUT TYPE=submit> </FORM>
"...it may be possible to construct a URL so that an attempt to perform a harmless idempotent operation such as the retrieval of an object will in fact cause a possibly damaging remote operation to occur. The telephone dialing URL, in particular, may cause an unwanted telephone call to be placed, possibly resulted in additional telephone charges to the user."Hmm, <IMG SRC="phone://011-964-1-123456"> might cost someone in the US a few bucks! All the same, interesting to think about e.g. White Pages as UI to phone: URLs., www.tvguide.com as UI to tv:, etc. (VCR+ numbering scheme, how relate to WebTV?).
This is a hypertext link to some JavaScript code
<A HREF="javascript:alert('What kind of URL is this?!')">This
is a hypertext link to some JavaScript code</A>
Helpful for testing out JS expressions (can even enter in location
bar of browser):<A HREF="javascript:"You are running " + navigator.userAgent> User-Agent</A>
<IMG SRC="javascript:get_image();"> <!-- doesn't work; see below -->For that need JS entity, which sort of like client-side includes. Entity: e.g., & for &. Entity replaced by its value. In JS entity, same thing. Difficult to show you because writing this doc in HTML, and hard to include an entity (even with &) without Netscape interpreting as actual entity. Netscape docs screw this up too. This is only way I've figured to show: & {foo};. An entity allows JS on right-hand side of HTML attributes (see example below); extension of SGML entity (HTML+ SGML). See http://home.netscape.com/eng/mozilla/3.0/handbook/javascript/getstart.htm#1016301. For example, the following returns a random map from Xerox.
{{JS any facility to seed random-number generator?}}
<SCRIPT>
function random(number) { return Math.random() * number; }
function maybe_neg(x) { return x * (Math.round(random(1)) ? -1 : 1); }
function get_image()
{
return "http://mapweb.parc.xerox.com/map/border/" +
"/lat=" + maybe_neg(random(180)) +
"/lon=" + maybe_neg(random(180)) +
"/wd=" + random(45) +
"/ht=" + random(45) +
"/format=.gif"; // must be at end of URL!
}
</SCRIPT>
<H1>Map from a random location</H1>
<IMG SRC="& {get_image()};">
<IMG SRC="javascript:while(1);">
"If Sarah in Ako and Lynne in Tucson are both developing new COM interfaces, how can they be certain that their identifiers don't conflict? We could adopt conventions similar to the solution for aircraft identification that N numbers represent and have a central authority, such as the FAA, manage the ID space. But while a central authority works for managing the relatively limited number of aircraft IDs, I doubt that a central software authority could work as well as the FAA managing the number of identifiers needed by the average program.Particularly embarassing in book on a technology that supposed to be "distributed architecture of the future" (as cover blurb says): answer sitting right under MS's nose: URLs. See later that term "unique" as often used meaningless, but in sense that MS using it (really mean global), DNS-based URLs guarantee "uniqueness." (See DNS & BIND.) MS makes problem sound much harder than is. Note p. 120 however that have readable ProgID ("Visio.Application.3", etc.), used by VB, but not guaranteed to be unique."GUIDs provide a much better solution. A unique GUID can be programmatically geneated without coordination with any central authority."
HKEY_LOCAL_MACHINE\SOFTWARE\Classes\CLSID\
{978C9E23-D4B0-11CE-BF2D-00AA003F40D0} -> "Microsoft Forms 2.0 Label"
Control -> ""
MiscStatus -> "2761105"
DefaultIcon -> "C:\WINDOWS\SYSTEM\FM20.DLL,0"
InprocServer32 -> "C:\WINDOWS\SYSTEM\FM20.DLL"
ThreadingModel="Apartment"
ToolboxBitmap32 -> "C:\WINDOWS\SYSTEM\FM20.DLL, 95"
ProgID -> "Forms.Label.1"
TypeLib -> {0D452EE1-E08F-101A-852E-02608C4D0BB4}
Version -> "2.0"
Implemented Categories
{7DD95801-9882-11CF-9FA9-00AA006C42C4}
{7DD95802-9882-11CF-9FA9-00AA006C42C4}
http://www.lmet.fr/cgi-bin/Cherche.cgi?ISBN=1568841698Got back:
This script should be referenced with a METHOD of POST. If you don't understand this, see this forms overview.So for some reason Cherche.cgi wants POST, not GET. Means using form. Form contains line like this, which user would fill out:
<INPUT TYPE="text" NAME="ISBN" SIZE=40 MAXLENGTH=255>But don't want user to have to fill out. Would like to pre-set for them somehow. Easy: turn INPUT TYPE="text" NAME="ISBN" into INPUT TYPE="hidden" NAME="ISBN" VALUE= the ISBN number! Then just need to give them submit button. Took while to figure out that two fields needed to be set for this to work (lmet CGI wants to know whether book, CD, or magazine):
ex16.html: <FORM ACTION="http://www.lmet.fr/cgi-bin/Cherche.cgi" METHOD=POST> <INPUT TYPE=hidden NAME=ISBN VALUE=1568841698> <!-- "Choisissez au moins LIVRE ou CD ou MAGAZINE!" --> <INPUT TYPE=hidden NAME="Book" VALUE=on> <INPUT TYPE=submit VALUE="Buy it!"> (Le monde en 'tique; Paris) </FORM>

<FORM ACTION="http://www.amazon.com/exec/obidos/ISBN=1568843054" METHOD=GET> <INPUT TYPE=submit VALUE="Order it!"> </FORM>
<TABLE BORDER=3><TR><TD> <INPUT TYPE=image SRC="http://www.idgbooks.com/images/smallcovers/1-56884-305-4.gif"> </TR></TABLE>
geturl -post Book=on&ISBN=1568841698 http://www.lmet.fr/cgi-bin/Cherche.cgi
{kind=link}
{kind=link}