[Table of Contents]
[Previous Section]
[Next Section]
How THOR Achieves Maximum
Performance
The THOR MPP Data Server™ platform consists of four to 288
processing nodes configured in a shared-nothing configuration.
THOR was designed from the ground up to be the first MPP solution
that is both massively parallel and inherently object oriented.
Of all MPP implementations, only THOR's SQL objectManager is truly
object-oriented: all data is encapsulated with the behaviors or
functions needed to operate on the data.
In this section of the White Paper, we describe how THOR's hardware
and software models support maximum performance in a number of
ways, including:
- Shared-nothing, MPP hardware configuration
- Unique toroidal mesh interconnect among processing nodes
- Uniform data distribution among nodes
- Underlying data-driven, object-oriented design
- Deadlock prevention via serialization instead of costly row
and table locking
- Partitioned and pipelined parallism
Why THOR uses a shared-nothing, MPP hardware
configuration
DSS/OLAP requires better scaling
There are significant advantages to an MPP architecture for processing
the complex queries which characterize the DSS/OLAP market. These
queries tend to be quite different from those in transaction processing.
They often touch large amounts of data, are normally quite I/O
intensive, and can run for very long times. They freely use SQL
operators such as joins and aggregations that require processing
large numbers of inter-row relationships, and thus they demand
much more in the way of computing resources than typical OLTP
queries. The result is that an architecture such as a shared-nothing
MPP system, which isolates processors, scales much better than
SMP for this workload.
Shared-nothing: definition
In a shared-nothing organization, the hardware is a set of processor
nodes connected by a communication network. Each node contains
its own CPU, memory, I/O bus, and disk storage. All communication
between processors is switched through the communications network.
The shared-nothing organization can be compared to two other MPP
hardware organizations:
- The shared-disk model, where each node has its
own private memory, but can directly access all disks.
- The shared-memory model, where all nodes can
directly access common memory and all disks.
Shared memory or shared disk systems don't scale
At first sight, common access to shared data should make it easier
to build a system, because any processor can have access to any
data item that it wants. In fact, this is the main source of bottleneck
problems. The intensive I/O activity in DSS/OLAP applications
must compete with the CPU for memory bandwidth. In SMP and shared-disk
or shared-memory MPP systems, as the number of CPUs increases,
contention for resources such as memory becomes more intense,
and performance suffers a severe impact.
Shared-nothing makes near-linear speedup and scale-up
possible
Because of THOR's shared-nothing architecture, the addition of
more processing nodes does not lead to memory, disk, or CPU bottlenecks.
In THOR's MPP implementation, each node has its own resources,
so contention remains essentially constant no matter how many
CPUs are added. In fact, the only contention in THOR is for communication
bandwidth, and communication bandwidth increases as nodes are
added, so never becomes a bottleneck.
This means that there is very little overhead relative to the
size of a system; if system A has twice as many nodes as system
B, system A will process queries and perform administrative
tasks roughly twice as fast as system B. This capability
ensures that managers can always scale a system appropriately,
and add processing power simply by adding additional nodes.
THOR's unique toroidal
mesh interconnect
For maximum performance, SQL objectManager must have homogeneous
connectivity among its nodes, with low latency, minimum interference
among the traffic on the network, and minimum path length between
source and destination nodes. THOR achieves this objective by
using a unique toroidal interconnect, managed by a dedicated set
of communication processors, one in each node.
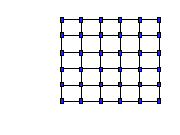
Envisioning the toroidal mesh
The toroidal interconnect can be visualized as follows. First,
imagine a rectangular connection grid with a processor node at
each intersection, as shown in Figure 4(a). Then connect
the processing nodes on the right to those on the left with added
network lines, forming a cylindrically connected system as shown
in Figure 4(b). Finally, envision connecting the nodes
in the top and bottom planes as shown in Figure 4(c).
The nodes are connected as if they were laid out on the surface
of a torus, or a doughnut shape.
 (a)
(a) 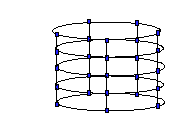 (b)
(b) 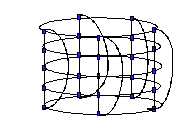 (c)
(c)
Figure 4.
Envisioning THOR's Toroidal Mesh
How nodes interconnect
Each node interconnects with the other nodes in a "nearest
neighbor" fashion. This connection employs special communication
processors to offload the CPUs and is more cost-effective than
other MPP systems that rely on multistage or crossbar switches
or require the CPU to participate in the data routing. It also
provides enhanced system availability through multiple path routing.
The toroidal mesh topology has the important property that the
array of processors is symmetric with respect to every node. Any
function can be assigned to any node, and it will perform as well
as if it had been assigned to any other node. This homogeneity
is the most efficient communication design for optimal execution
of the SQL objectManager software.
Uniform data distribution among nodes
THOR uses processor affinity, combined with a proprietary
hashing algorithm, to automatically and uniformly
distribute database rows among processor nodes.
Why is uniform data distribution important?
For parallel processing to achieve optimum performance, table
rows must be distributed evenly among a system's processors. If
four processors each contain 1000 rows, for example, and if the
processors work in parallel, the time it takes to process all
4000 rows is roughly comparable to the time it takes to process
1000 rows. However, if one processor contains 2500 rows and the
others contain 500 rows each, the time it takes to process all
4000 rows is roughly comparable to the time it takes to process
2500 rows, or all the rows on the overloaded processor.
Uniform distribution, therefore, maximizes parallel processing
performance for many operations.
Affinity: definition
A technique sometimes used to distribute data among nodes is called
affinity. The term comes from the fact that each data item
has affinity for a processor. Each processor is given a part of
the database to manage, and all requests for that data are routed
through that processor. THOR's shared-nothing system implements
affinity; each processor accesses data and memory on its own disks.
Hashing: definition
To determine which row has affinity with which node, THOR uses
a proprietary hashing algorithm. A hashing algorithm is simply
a formula that generates a number indicating to which node a row
should be assigned.
How THOR generates hash values
THOR's hashing algorithm uses a large random number, in conjunction
with the primary index of a row, to generate the row's hash value.
Bits from the hash value are used to select the node where the
row resides.
To ensure even data distribution, the THOR SQL objectManager requires
that the primary index for a table be unique. If a table has no
primary unique index, THOR generates a synthetic hash value that
ensures "round-robin" distribution of data to nodes.
Data-driven, object-oriented design
The software design of THOR is based on
a data-driven model of execution, implemented using object oriented
technology. Data-driven processing and object orientation combine
to yield a product which is truly unique today, but which will
be the paradigm for the next generation of implementations by
other vendors.
A brief description of data-driven processing
Data-driven processing finds multiple operations that can be undertaken
concurrently within the evaluation of one or more expression.
Data-driven processing is inherently parallel, and overcomes the
limitations of procedural programming, in which each statement
must complete execution before the next statement begins. This
model lets THOR process and evaluate many queries at the same
time, further increasing performance.
How queries are executed
As each user query comes in, it is assigned to the next available
node in a "round robin" fashion. It is possible to do
this only because the node array is symmetric with respect to
each node, and because every node in the system can perform all
the functions of the database system.
The assigned node is referred to as the initiating node or query
captain for that query, and is responsible for:
- Parsing the query
- Optimizing the query
- Breaking the query down into tokens, or messages
- Obtaining serialization tags
- Accumulating the final results and performing the final aggregations
- Coordinating the transaction commit
Multiple nodes act as query captains for multiple queries in parallel,
which leads to greatly improved performance. Figure 5 shows
a simplified schematic of THOR's toroidal mesh, illustrating how
the query captain and the nodes communicate.
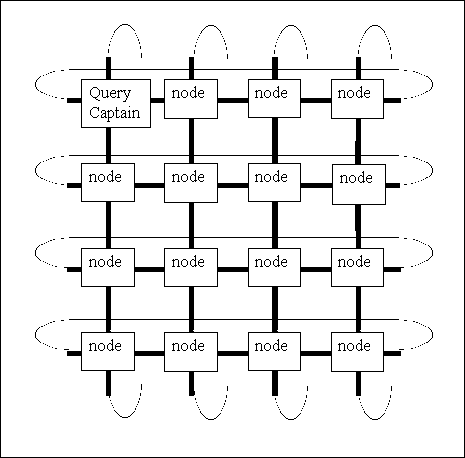
Figure 5.
How nodes communicate during a query
As discussed in "Uniform data distribution among nodes"
on page 11, each node is given a part of the database to
manage, and all requests for that data are routed through that
processor. This feature means that each node contains specific
data, in the form of row objects.
Following is a simplified description of the procedure THOR uses
to process and execute a query.
Step 1 - The query captain prepares and distributes the query
At the initiating node, the query is parsed, analyzed, and
optimized. This process defines a plan of execution for the database
node software. The plan is then broadcast via messages to all nodes
for execution by their row objects.
Step 2 - The row objects process the query
Each row object determines whether it matches the query criteria
and, if so, how it needs to compute and distribute data to successive
objects or back to the query captain. The row objects communicate
among themselves via messages to complete execution. As results for a set of rows on a node are available, the
nodes distribute interim results to other row objects or back
to the query captain.
Step 3 - The query captain assembles and returns results
As results are pipelined in from the processing nodes, the
query captain performs any final aggregations and calculations.
When all results have been returned and all processing has
been completed, the query captain returns the final results to
the requester.
Summary
As the steps above illustrate, the only tasks that occur sequentially
during a query are those performed by the query captain. All primary
database processing takes place in parallel on all nodes at once.
THOR's unique method of distributing query initiation tasks among
all nodes in the system, coupled with its data-driven and object-oriented
approach to query processing at the node level, means that a large
number of queries can be processed in parallel (inter-query parallelism).
It also means that a single query can be processed in parallel
on all nodes at once (intra-query parallelism.) In this way, THOR
fully maximizes the parallel capabilities of its hardware and
software system.
Inter- and intra-query parallel processing are discussed in more
detail in "Partitioned and pipelined parallelism" on
page 15.
Preventing deadlock
In the past, parallel DBMS implementations have been severely
affected by deadlock contention. Reducing deadlock contention
has been a problem both for efforts to process multiple queries
in parallel and for efforts to process a single query in parallel
across multiple nodes.
Lock table can lead to bottlenecks
A common solution to this problem is for the software to mark
pages as locked so that one processor can finish making its update
before other processors are allowed to use the data. Unfortunately,
the lock table is often centralized, and as more processors are
added, the lock table becomes a bottleneck that limits system
performance.
Serialization replaces the lock table
With data-driven as with any other execution model, it is necessary
to ensure that operations take place in the correct order. In
place of row-level or table-level locking, THOR uses a data-driven
technique called serialization for most operations. The
function of serialization is to make explicit which operations
must precede other operations, and which can proceed at the same
time.
Serialization tickets
Each operation that needs to be carried out (INSERT, UPDATE, SELECT,
etc.) is assigned a serialization ticket. For each row
object that requires a ticket, the row object is looked up and
its serialization counters are incremented. Operations are then
executed in the order that the tickets were issued. Once an operation
has been issued tickets, the statement is serialized.
Tickets have two important properties:
- Tickets are just numbers, and thus are very fast and easy
to issue.
- Tickets allow a row object to make a local decision about
the order in which operations are executed.
Ticket generation is the only centralized function in THOR's software.
Read and write processes isolated
Each operation receives both a read and a write ticket, so that
any number of reads can be carried out until a ticket for a write
operation comes along. At that point, other read and write operations
must wait only for the brief instant while the write operation
is completing.
The major benefits of serialization
Serializing a statement has several important benefits:
- Many transactions that are deadlocked on other RDBMS systems
are deadlock-free and restart-free on THOR.
- Even though the query may execute on many processors in parallel,
all decisions about ordering operations can be made locally by
the row objects. This minimizes inter-node communication, thus
speeding up query processing.
- Serialization provides distributed concurrency control, and
replaces the lock manager. There is no need for any other concurrency
control mechanism.
Serialization and ACID principles
Serialization also assures that transactions meet the ACID principles
for proper transaction processing. ACID stands for the following
properties:
- Atomicity - The transaction is an atomic unit, consisting
of a single collection of actions that is either completed in
full (committed) or aborted in full (rolled back).
- Consistency - All integrity constraints of the database
are fulfilled after the transaction has finished, thus leaving
the database in a consistent state.
- Isolation - A transaction must be processed in apparent
isolation. Data used by a transaction cannot change while the
transaction is being processed. Similarly, other transactions
can't use the results of the current transaction until it is committed
or aborted.
- Durability - Once a transaction commits, its results
must be durable, even in the case of software or hardware failures.
Partitioned and pipelined parallelism
All of the features discussed above work in concert to enable
two forms of parallel processing, partitioned and pipelined. Each
of these is briefly described in this section.
Partitioned parallelism improves intra- and inter-query
performance
Partitioned parallelism refers to a system's ability to
distribute a single query across multiple nodes at the same time.
For example, imagine you have to go through the phone book to
find the name of someone whose phone number you have. Obviously,
this could take a very long time. Now imagine that the phone book
is divided up into 100 sections of equal size, and 100 people
are simultaneously looking for that name. The result will be found
in approximately 1/100 the time. This is analogous to one of the
primary ways THOR maximizes intra-query processing performance.
Partitioned parallelism also refers to a system's ability to perform
multiple queries on a node at the same time. Returning to our
phone book example, this time imagine that your 100 people have
to find two names instead of one. Instead of looking for only
one name, each person can be looking for both names at the same
time. Because both queries ("find a name") are being
executed in parallel, results will be returned in less time than
if the queries were processed in serial, one after the other.
This is analogous to one of the primary ways THOR maximizes inter-query
processing performance.
Pipelined parallelism improves intra-query performance
Pipelined parallelism refers to a system's ability to begin
feeding results back as they are available. Continuing our phone
book example, imagine this time that you have to produce a sorted
list of all people whose phone number begins with 234. If you
are the query captain (as described in "How queries are executed"
on page 12), you are responsible for sorting the names your
100 workers find.
Instead of waiting for each of your workers to find all the matching
names, you ask them to hand you their list of names in sorted
batches of 20 at a time. Each time you receive another sorted
20 names, you inter-sort them with the other names you have already
received and sorted. In this way, names are being sorted almost
as fast as they are being found; there is no significant delay
between finding all the names and producing a sorted list. This
is analogous to another primary way THOR maximizes intra-query
processing performance.
[Table of Contents]
[Previous Section]
[Next Section]