[Table of Contents]
[Previous Section]
[Next Section]
THOR's Turnkey Solution
Introduction
THOR™ is a complete turnkey system, comprising:
- THOR MPP Data Server™ hardware - simple hardware
optimized to provide a cost-effective platform for the SQL objectManager
software
- THOR SQL objectManager™ software - an
object relational SQL implementation designed to run on parallel
shared-nothing hardware
The following sections briefly describe how THOR satisfies the
criteria of being easy to administer, scaleable, extensible, and
open.
THOR is easy to administer
Introduction
Because of THOR's unique methods of data
distribution and parallel processing, THOR is able to dispense
with many time-consuming administrative tasks that other systems
require. THOR also implements a variety of features to ensure
RAS.
Automatic data partitioning
THOR SQL objectManager distributes and partitions data across
nodes via a proprietary hashing algorithm. Hashing provides a
uniform data distribution, which leads to very good load balancing.
Administrators no longer have to consider partition size and location
issues as their databases grow in size.
Automatic query optimization
THOR uses a proprietary, highly tuned, cost-based query optimizer
to speed up the processing of SQL queries. Administrators and
programmers no longer have to tweak, tune, and test the majority
of their queries to enhance performance.
Extensive RAS features
THOR incorporates a number of hardware and software design elements
to minimize the possibility of system crashes, and to enable rapid
recovery from any system problems. These features are briefly
listed below.
- Hardware
- N+1 redundant power supplies
- Environmental monitoring
- Diagnostics suite
- Front-accessible disk drives
- ECC protected memory and memory bus
- Flash upgradeable firmware
- Software
- Data and log mirroring across nodes
- Support for ACID transaction principles
- Parallel backup and restore
- Remote system monitoring and configuration
THOR is scaleable
Introduction
THOR's shared-nothing approach, combined
with its unique data-driven implementation, provides processing
that is more inherently parallel and easier to distribute among
processors than current implementations.
Shared-nothing approach
A shared-nothing approach means that each processor node
on the system has its own memory, hard disk, CPU, and communications
connections. Shared-nothing systems can provide linear speed-up
and scale-up for up to thousands of processors, because they don't
have the resource bottlenecks of shared-memory and shared-disk
systems.
Data-driven implementation
Data-driven implementation means that queries are divided
into discrete tasks that are executing at the same time on multiple
processors. The transaction is complete when all the tasks are
complete and the results assembled in the proper order.
THOR is extensible
Introduction
THOR was designed and implemented using
object-oriented (OO) design tools and techniques, and is programmed
to understand relational operators within this context.
Native OO support and native
relational support
As with any OO system, THOR's OO design incorporates classes,
attributes, and instances. The OO design is in contrast to the
existing major RDBMS systems, which are based on procedural programming
models. Because of their procedural nature, they have often had
to be extensively rewritten to support major enhancements, frequently
resulting in implementations that were poorly designed or that
suffered severe performance problems.
THOR is also designed to understand row and column data and their
associated relational operators. THOR easily performs relational
operations on both traditional data types and on new, complex
data types.
BLOB support
THOR also implements Binary Large Object (BLOB) support for new
data types such as video, audio, and bitmaps. The object programming
model guarantees that THOR is extensible for new data types and
for defining new operations on data.
Easy support for new data types
Let's consider a simple example of a data type extension to SQL.
Suppose we want to create a database of fingerprints. For each
fingerprint in the database, we want to store some traditional
SQL type data about when and where it was collected, to whom it
belongs, etc.
In addition, we want to store the fingerprints themselves as part
of the database. Since fingerprint is not a legitimate data type
in SQL, we will need to add one or more new data types. For simplicity,
we'll assume that one new data type will suffice.
Adding predicates for the new data type
Object capability allows developers not only to create new data
types, but also to create new predicates, such as SIMILAR and
PARTIAL, for the new data type FINGERPRINT. These predicates are
evaluated by invoking calculation functions which the developer
supplies, and which reside within the database just as EQUAL functions
do today for each of the data types currently supported by SQL.
Querying on the new data type
The newly defined predicates can be used as qualifiers within
a WHERE clause in SQL for queries to the fingerprint database.
This makes it possible, for example, to screen the database for
suspects in a particular crime based on similarity of fingerprints
on file to one found at the scene. One way such support might
be implemented is shown in the following pseudo-SQL example.
SELECT IMAGE, NAME, AGE, SEX, HT, WT, DOB AS SUSPECT
FROM TAKENPRINTS
WHERE SIMILAR (IMAGE, SAMPLE)
AND NOT PARTIAL(IMAGE)
...
Web pages and data type support
Another interesting example of how THOR supports new data types
is the World Wide Web. Typical web sites offer several types of
data, including text, pictures, movies, and sounds. THOR can support
this mixed environment, especially when the requirement is for
ad-hoc searches and queries.
For example, a retail site might let a customer look up a specific
type of suit based on certain criteria, such as color, cost, and
fabric. THOR can return a picture of the suit, a movie clip of
a model presenting it, and voice-over of the features. THOR and
the World Wide Web can be a very powerful combination.
THOR is open
Introduction
By providing support for open interfaces,
THOR preserves your investment in standard tools and applications.
In fact, THOR SQL objectManager supports both standard SQL, through
open interfaces such as the ODBC API, and the SYBASE Open Client/Server
APIs, including TransactŁSQL and DB/Net libraries.
Standard SQL gateway support
Figure 1 illustrates the arrangement of the THOR MPP Data Server relative
to other computing devices in the data warehouse environment.
THOR's standard SQL gateway allows the THOR server to accept data
from a variety of sources, and to act as either a data warehouse
or a data mart.
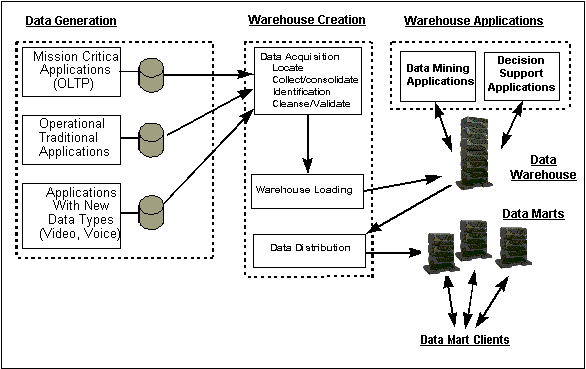
Figure 1.
THOR in the data warehouse environment
Open architecture
Figure 2 illustrates
THOR's open system architecture, and how it presents a single
database view to the user.
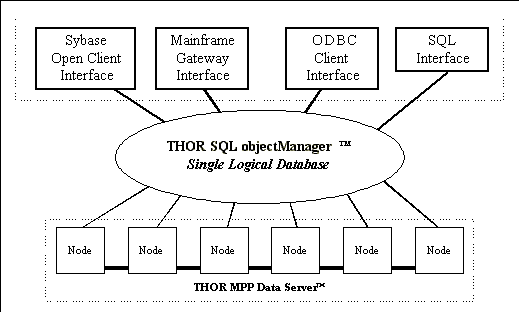
Figure 2.
THOR's open system architecture
SYBASE Open Client and Transact-SQL support
THOR also supports SYBASE's TransactŁSQL, an API that includes
the SQL command set, and SYBASE's SQL Manager Open Server/Open
Client APIs. This means that THOR supports many of the data types,
SQL, stored procedures, and triggers compatible with SYBASE, one
of the most widely used, open client-server platforms available
today.
Figure 3 shows a possible THOR implementation, in which THOR fully
participates with an existing SYBASE Open Client implementation.
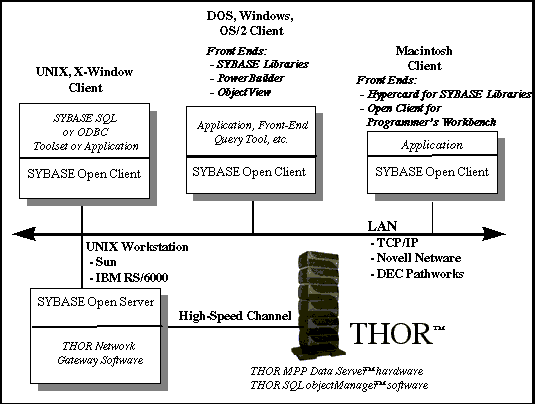
Figure 3.
A THOR implementation using SYBASE Open Client
Plug-and-Play support
Application programmers who are using the latest application builder
suites (e.g. PowerBuilder from SYBASE, Visual Basic from Microsoft,
etc.) can create plug-and-play applications that interface with
THOR's SQL architecture.
[Table of Contents]
[Previous Section]
[Next Section]